Classifier des millions d’images de plancton : pourquoi les petits modèles suffisent
Computer vision
ML océano
Un benchmark complet de méthodes de machine learning pour la classification d’images de plancton révèle que la simplicité l’emporte souvent sur la complexité.
Mots clés
classification d’images, plancton, deep learning, CNN, benchmark, computer vision
Petit mais costaud : ce que le plancton nous apprend sur le machine learning
Quand la simplicité bat la complexité en classification d’images
Cet article s’appuie sur mes travaux publiés dans Earth System Science Data :
Panaïotis, T., Amblard, E., Boniface-Chang, G., Dulac-Arnold, G., Woodward, B., & Irisson, J.-O. (2026). Benchmark of plankton images classification: Emphasizing features extraction over classifier complexity. Earth System Science Data, 18(2), 945–967, 10.5194/essd-18-945-2026.
Le code est disponible sur Zenodo.
Image d’en-tête : Visualisation interactive de réseau de neurones par A. W. Harley (2015)
Le problème : des millions d’images à trier
Imaginez devoir trier 1,6 million de photos. C’est le quotidien des océanographes qui utilisent des instruments d’imagerie pour étudier le plancton. Ces organismes sont essentiels aux écosystèmes marins et incroyablement divers : des milliers d’espèces différentes, de toutes tailles et formes. Le défi ? Dans les images, ils côtoient beaucoup de « pollution » : bulles, détritus, particules de neige marine1.
Impossible de tout faire à la main. Le machine learning est devenu indispensable. Mais quelle approche choisir pour notre plancton ? Les réseaux de neurones à convolutions (CNN), les plus récents Vision Transformers (VIT), véritables machines de guerre, ou faut-il en rester à des méthodes plus classiques et compréhensibles ?
Par ailleurs, la plupart des études sur le sujet utilisent des petits jeux de données maison, jamais publiés, qui ne reflètent pas la réalité du terrain. Difficile de savoir ce qui marche le mieux.
Pour répondre à cette question, nous avons mené un benchmark systématique sur 6 jeux de données réels d’images de plancton.
Pourquoi c’est si difficile ?
Classifier des images de plancton n’est pas un problème standard de computer vision. Plusieurs spécificités rendent la tâche particulièrement ardue.
1. Des images pauvres en information
Les instruments d’imagerie planctonique produisent des images :
- petites : souvent ~100×100 pixels ou moins ;
- en niveaux de gris : pas de couleur pour aider à la distinction ;
- de faible résolution : optimisées pour la vitesse, pas forcément la qualité.
À titre de comparaison, les grands modèles sont entraînés sur des images couleur de bonne qualité (comme ImageNet). Nos images de plancton ? Petites, grises, pauvres en détails. On joue dans une autre catégorie.

2. Une distribution complètement déséquilibrée
Voici la composition réelle de nos jeux de données :
- dataset IFCB (Sosik, Peacock, et Brownlee 2015) : 1,6 M d’images, mais 12,6% seulement de plancton (le reste : débris) ;
- dataset UVP6 (Picheral et al. 2024) : 634k images, 7,7% de plancton ;
- dataset ZooScan (Elineau et al. 2024) : 1,45 M d’images, 71,2% de plancton.
NotePourquoi tant de différence dans la composition ?
Les instruments in situ (IFCB, UVP6) imagent directement dans l’océan : ils capturent tout ce qui passe devant l’objectif, y compris énormément de particules non-vivantes (débris, bulles, agrégats). D’où le faible pourcentage de plancton.
Les instruments ex situ (ZooScan) imagent des échantillons prélevés au filet puis scannés au laboratoire : le plancton est plus concentré, mais on perd les organismes fragiles qui ne survivent pas à la capture.
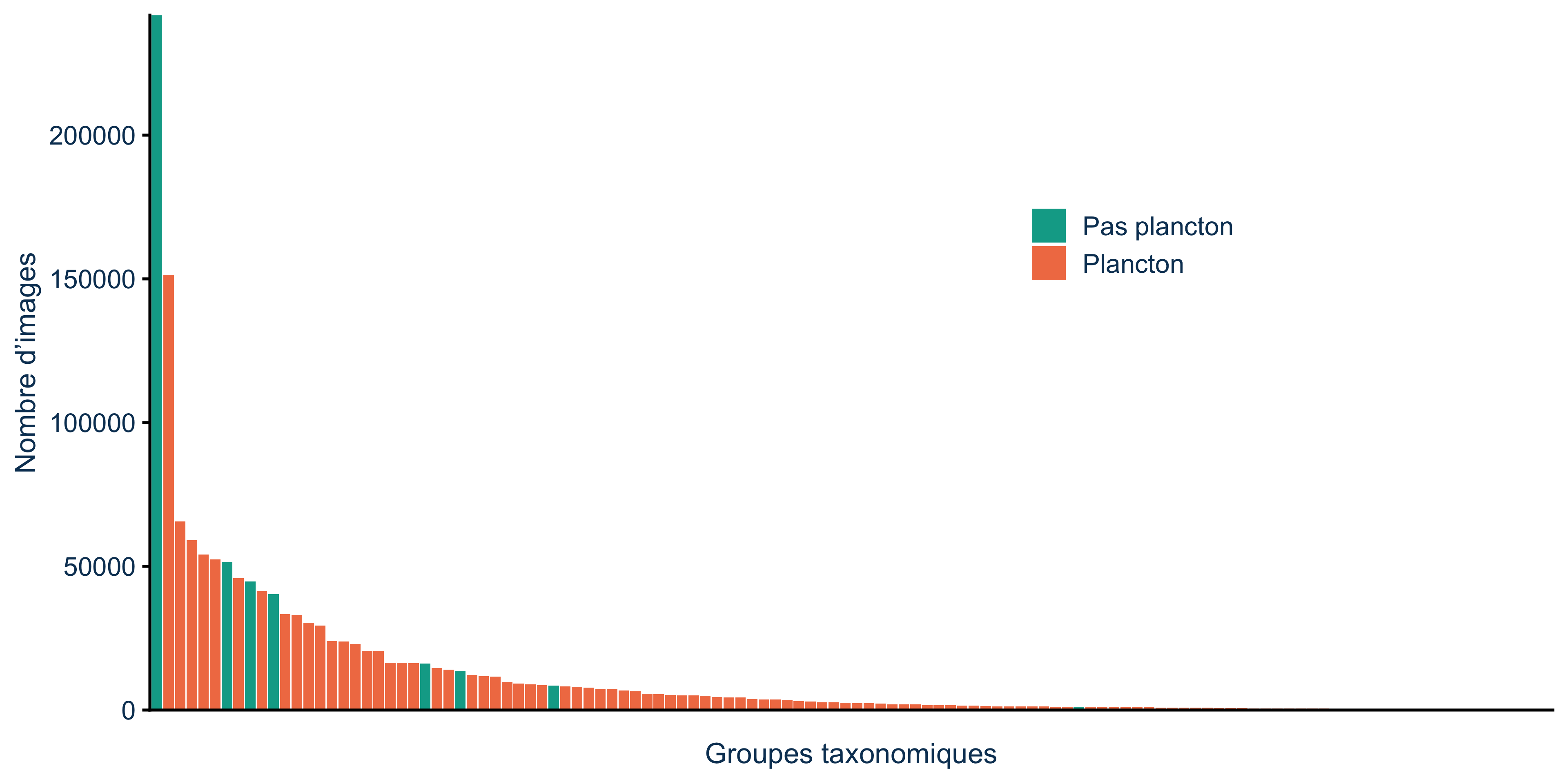
Et parmi le plancton ? Certaines espèces apparaissent 150 000 fois, d’autres… 70 fois. C’est typique des communautés planctoniques : quelques espèces dominantes, beaucoup d’espèces rares (Figure 1).
3. Le piège de l’accuracy
Imaginez un classifieur ultra-simple qui prédit “détritus” pour toutes les images du dataset IFCB.
Son accuracy ? 87,4% !
Impressionnant, non ? Sauf qu’il ne reconnaît aucun organisme planctonique.
C’est pourtant ce qui arrive quand on optimise uniquement l’accuracy sur des données déséquilibrées : le modèle apprend à bien classifier les classes dominantes (qui pèsent lourd dans le calcul) et ignore les classes rares (qui ne pèsent presque rien).
Or, ce sont justement les espèces rares qui intéressent souvent les biologistes. Un modèle à 95% d’accuracy qui rate systématiquement les larves de poissons n’est pas très utile.
C’est pour ça que nous utilisons des métriques plus représentatives : balanced accuracy (moyenne des performances par classe), précision et rappel par classe, et des métriques calculées uniquement sur le plancton (en excluant les débris).
Ce que nous avons fait
Nous avons créé le premier benchmark réaliste pour la classification d’images de plancton :
- 6 jeux de données provenant d’instruments différents (FlowCAM, IFCB, ISIIS, UVP6, ZooCAM, ZooScan) ;
- entre 300 000 et 1,6 million d’images par jeu de données ;
- entre 32 et 120 classes par jeu de données ;
- des données réelles et déséquilibrées : certaines classes sont très rares, d’autres dominent (souvent les débris !).
Nous avons testé systématiquement plusieurs approches :
- l’approche classique : extraction manuelle de features (forme, taille, texture) + Random Forest ;
- des CNN de différentes tailles : du petit MobileNetV2 au mastodonte EfficientNetV2 XL ;
- des approches hybrides : combiner les forces des deux.
Pour évaluer ces modèles, nous avons utilisé plusieurs métriques complémentaires, adaptées aux spécificités des données planctoniques (déséquilibre, classes rares, dominance des débris) : accuracy, balanced accuracy, précision moyenne des classes planctoniques, rappel moyen des classes planctoniques.
NoteComprendre les métriques utilisées
accuracy : proportion d’objets correctement classés. Simple mais trompeur sur des données déséquilibrées (un modèle qui prédit toujours “détritus” peut avoir 80% d’accuracy !) ;
balanced accuracy : moyenne des performances par classe. Chaque classe compte autant, qu’elle soit rare ou abondante. Métrique plus juste pour nos données déséquilibrées ;
précision moyenne (plancton) : parmi les objets prédits comme plancton, quelle proportion l’est vraiment ? Mesure la “pureté” de nos classes planctoniques ;
Exemple : si le modèle prédit 100 copépodes et que 80 le sont vraiment, la précision pour les copépodes est de 80%. On moyenne ensuite sur toutes les classes planctoniques.
rappel moyen (plancton) : parmi tous les objets planctoniques, quelle proportion a été détectée ? Mesure notre capacité à ne pas rater d’organismes.
Exemple : s’il y a 100 copépodes dans le test set et que le modèle en détecte 75, le rappel pour les copépodes est de 75%. On moyenne ensuite sur toutes les classes planctoniques.
Ce que nous avons découvert
1. Les CNN gagnent… mais pas toujours
Les CNN surpassent l’approche classique, c’est vrai. Mais creusons un peu (Figure 2) :
- Sur l’accuracy globale ? L’amélioration est modeste.
- Sur la balanced accuracy (moyenne des performances par classe) ? Là, c’est une vraie différence !
- Sur les métriques spécifiques au plancton (précision et rappel) ? Gain significatif, surtout pour le rappel !
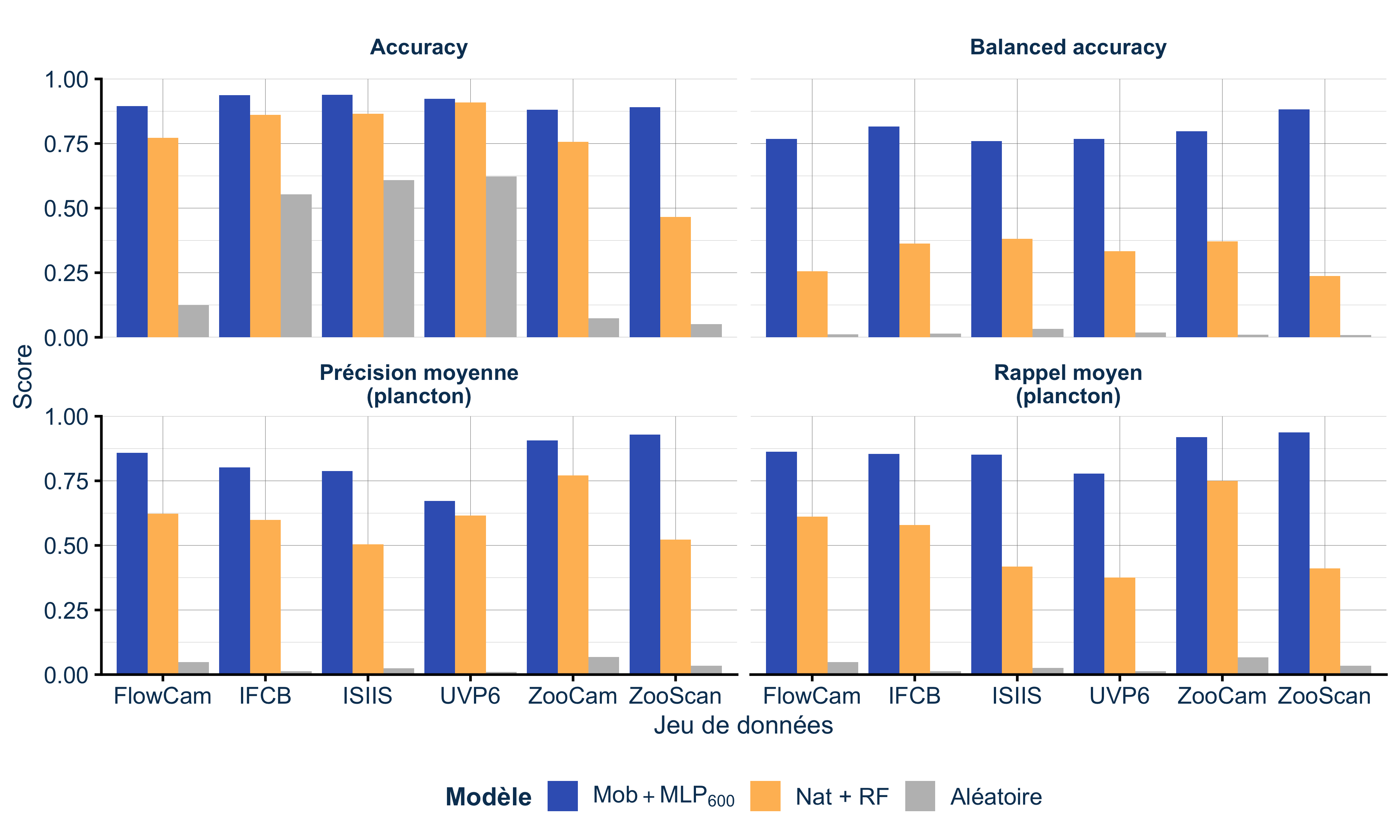
Traduction : si vous avez beaucoup d’exemples d’une classe, une méthode simple marchera très bien. Les CNN brillent surtout quand les données sont rares, précisément le cas des espèces planctoniques intéressantes pour les biologistes.
Notez aussi le rôle du classifieur aléatoire : il obtient 55 à 63% d’accuracy sur les datasets dominés par les débris (IFCB, ISIIS, UVP6) simplement en prédisant toujours “détritus”. C’est pour ça que nous privilégions les autres métriques, qui révèlent la vraie performance.
2. Plus gros n’est pas toujours mieux
Voici la vraie surprise : un petit CNN (MobileNetV2) performe aussi bien (voire moins bien) qu’un gros (EfficientNetV2 XL) (Figure 3).
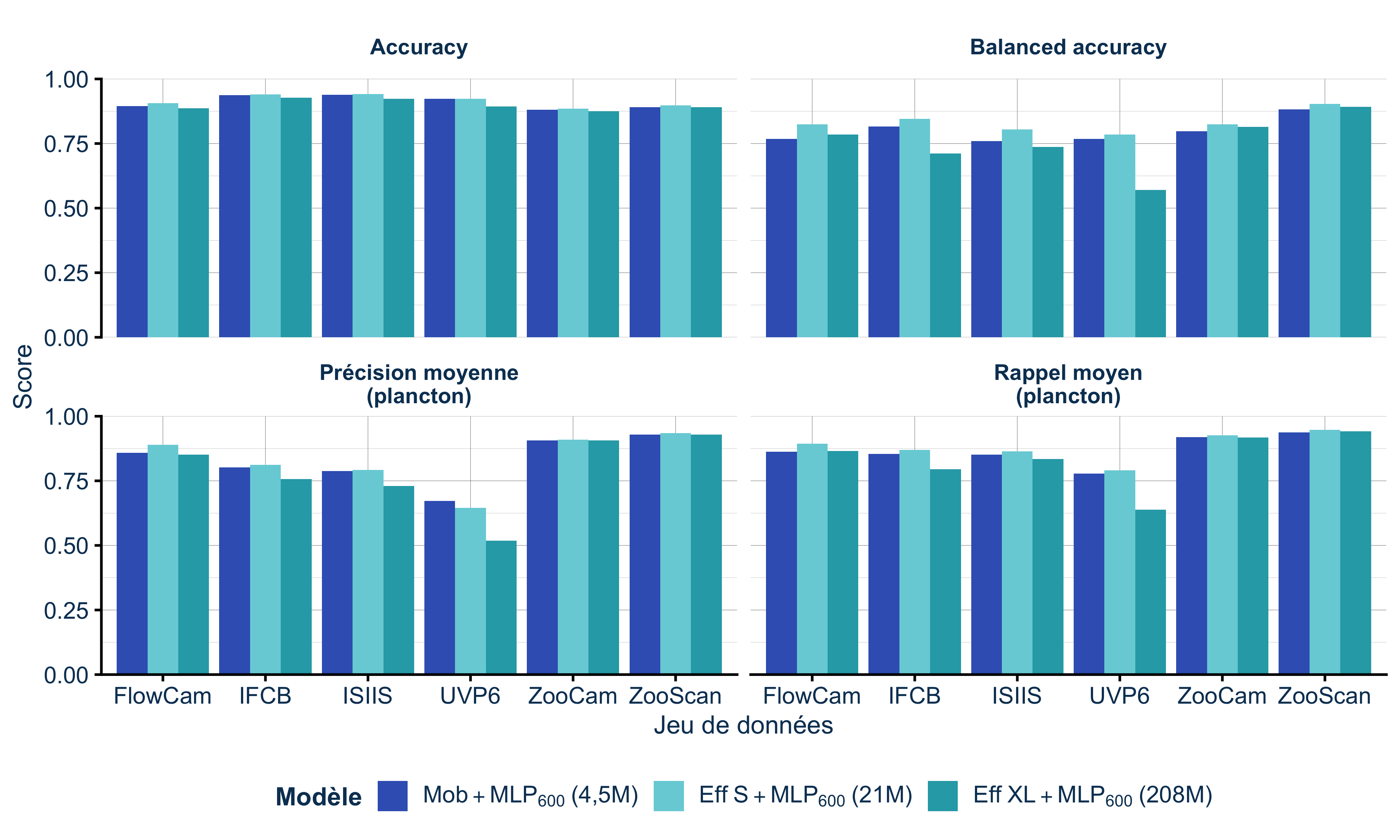
Pourquoi ? Les images de plancton sont petites (~100×100 pixels) et en niveaux de gris. Il n’y a tout simplement pas autant d’information à extraire qu’on pourrait le penser.
Le gros modèle (208 millions de paramètres) n’a rien de plus à apprendre qu’un petit (4,5 millions). Il sur-ajuste même parfois sur le dataset UVP6, le plus petit et le plus déséquilibré de notre étude.
Et si on compresse encore plus ?
Plus étonnant encore : on peut compresser les caractéristiques extraites par le CNN de 1792 à seulement 50 valeurs via une analyse en composantes principales (ACP) sans perte de performance (Figure 4).
3. Les features > le classifieur
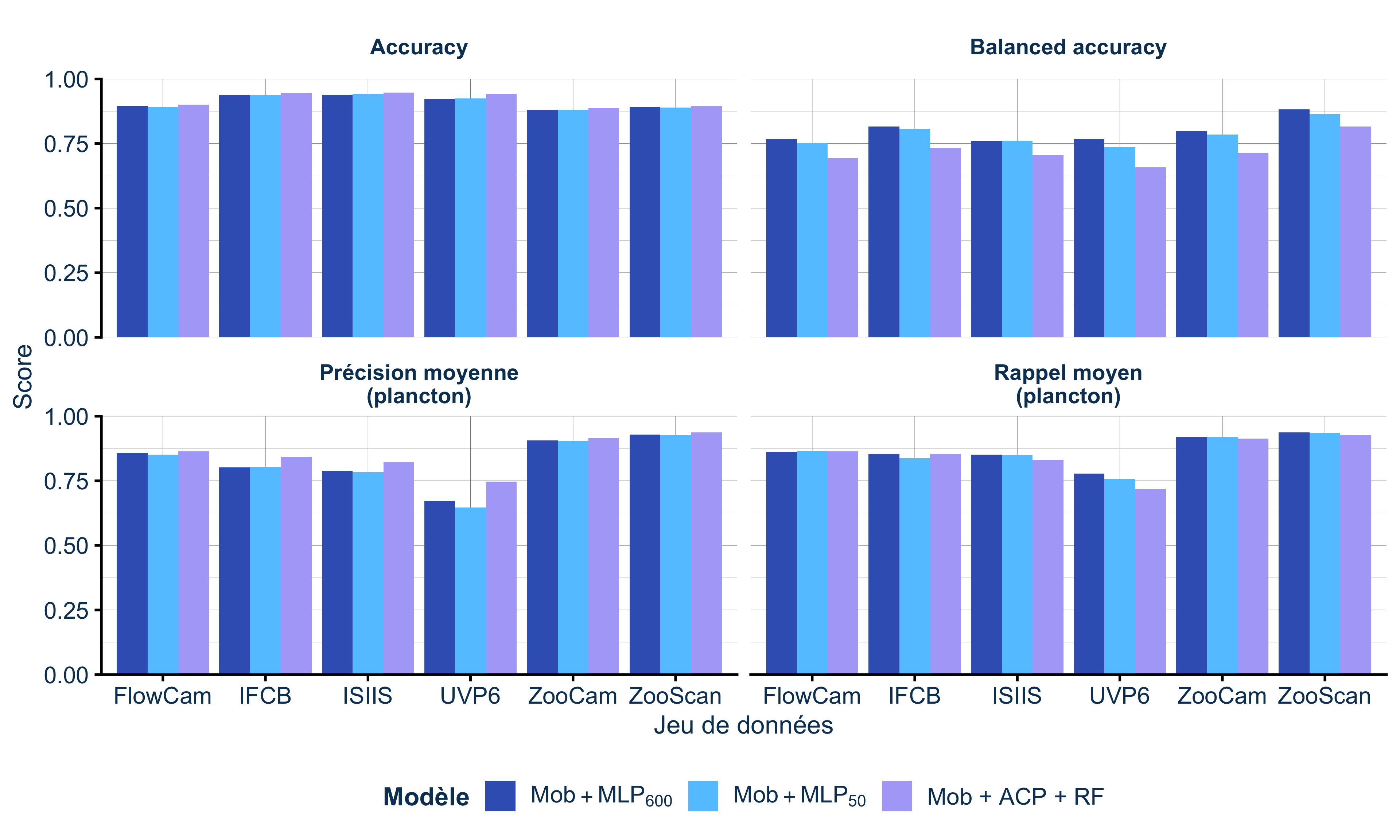
Peu importe que vous utilisiez un Random Forest ou un réseau de neurones pour faire la classification finale. Ce qui compte vraiment, c’est la qualité des features (ou caractéristiques) que vous extrayez des images (Figure 5).
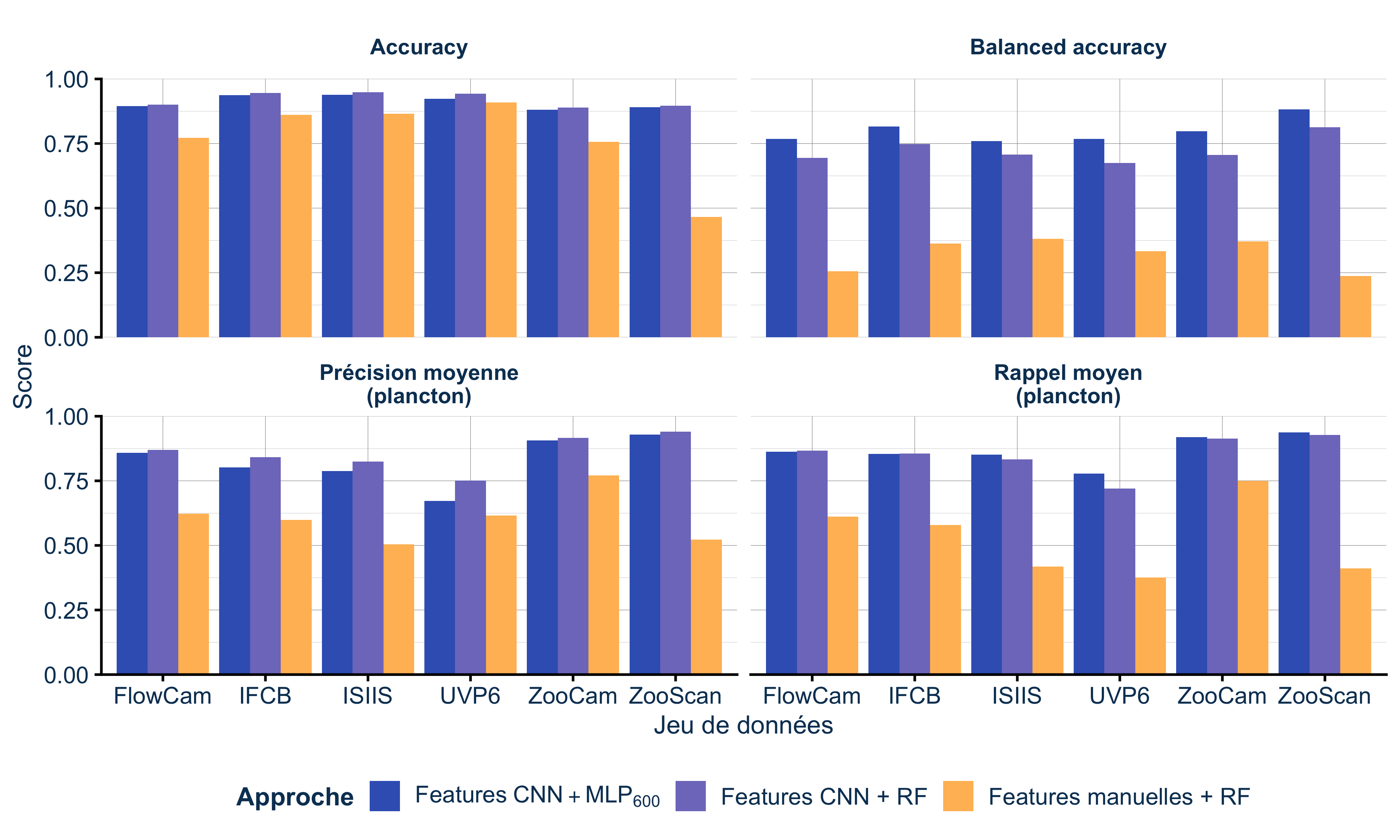
Ce que montre cette figure :
- Features manuelles + RF : performances moyennes
- Features CNN + MLP₆₀₀ : excellentes performances
- Features CNN + RF : excellentes performances, quasi identiques au MLP
Traduction : changer de classifieur (MLP → RF) en gardant les bonnes features (CNN) ne change presque rien. Mais garder le même classifieur (RF) en changeant de features (manuelles → CNN) change tout !
C’est pour ça que les CNN marchent mieux : ils apprennent automatiquement les bonnes caractéristiques, alors qu’avec l’approche classique, il faut les définir à la main (et on passe souvent à côté de détails importants comme les textures fines).
4. L’importance des poids de classes
Sur des données aussi déséquilibrées, pondérer les erreurs par l’inverse de la fréquence des classes change tout (Figure 6).
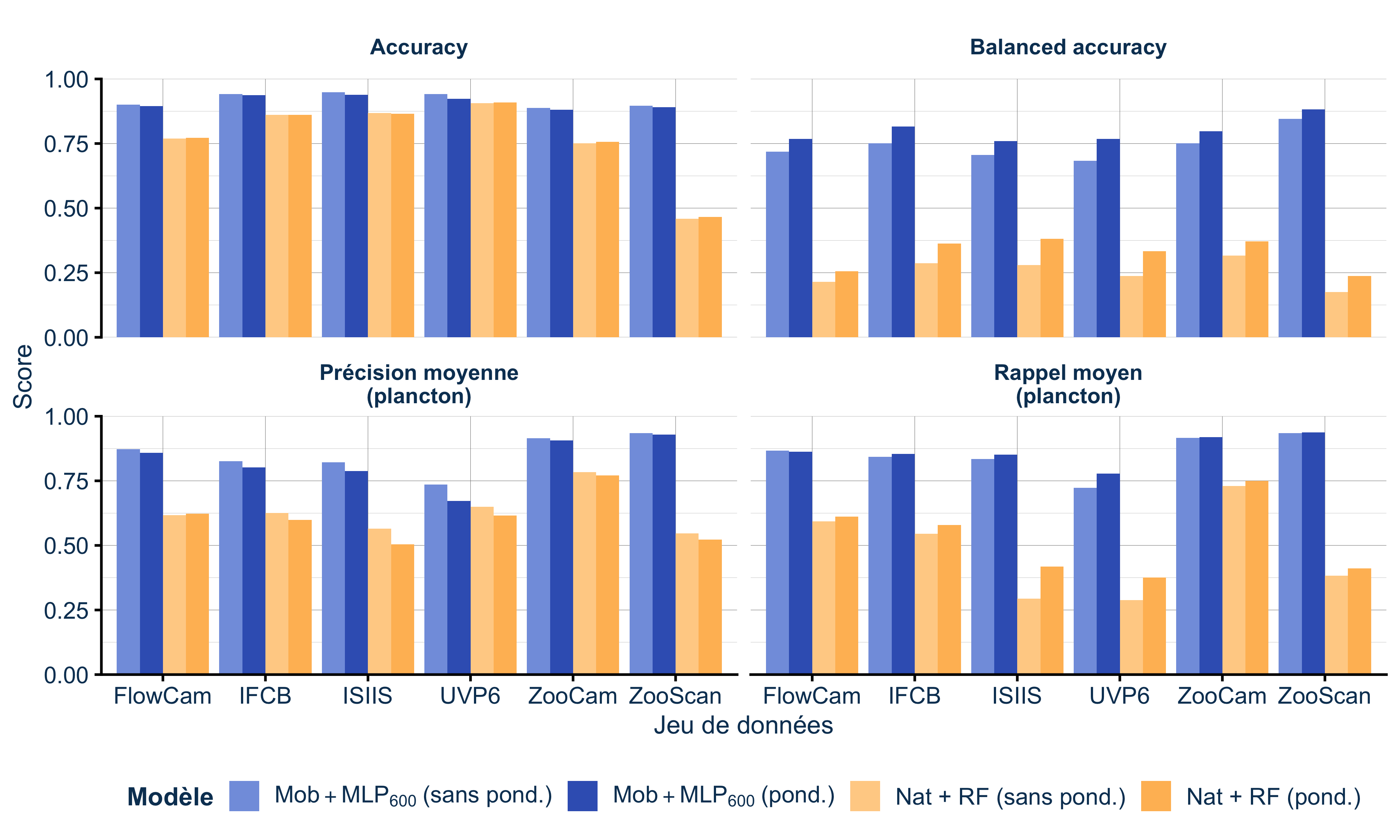
La pondération améliore significativement les performances, surtout pour le Random Forest, pour les CNN le gain est plus modeste mais reste significatif.
Sans pondération, les modèles apprennent surtout à bien classifier les débris (majoritaires) et négligent les espèces rares. Avec pondération, on force le modèle à accorder autant d’importance à une larve de poisson rare qu’à un copépode2 abondant.
La pondération améliore le rappel (on rate moins d’organismes rares) mais peut légèrement diminuer la précision (un peu plus de “faux positifs” parmi les classes planctoniques). C’est un compromis acceptable quand l’objectif est de ne pas manquer les espèces rares.
Les leçons pratiques
Pour ceux qui travaillent avec des images
- commencez simple : un petit CNN bien entraîné bat un gros modèle mal maîtrisé ;
- comprenez vos données : si vos classes sont très déséquilibrées, pondérez vos erreurs ;
- ne vous fiez pas qu’à l’accuracy : regardez les performances par classe (balanced accuracy, précision/rappel) ;
- l’équipement compte : de meilleures images (couleur, résolution) aideront plus qu’un modèle plus gros.
Le mythe des transformers
Les vision transformers sont à la mode en computer vision, mais pour les images de plancton le gain qu’ils apportent est marginal (Maracani et al. 2023), tout en demandant beaucoup plus de données et de calcul. Ce n’est pas que les transformers soient mauvais. C’est que pour des images petites, simples et en niveaux de gris, un petit CNN capte déjà toute l’information disponible. Ajouter de la complexité n’apporte rien quand le signal est déjà entièrement extrait.
Ce que ça change concrètement
- modèles opérationnels plus légers : pas besoin de GPU énormes, des modèles qui tournent vite ;
- entraînements plus rapides : quelques heures au lieu de jours ;
- plus accessible : vous n’avez pas besoin d’une infrastructure cloud massive.
Et pour vous ?
Ces principes s’appliquent bien au-delà du plancton. Si vous travaillez avec :
- des images médicales petites/simples ;
- des images de surveillance qualité ;
- des données où certaines catégories sont très rares ;
- des contraintes de temps/budget.
…alors la leçon est la même : commencez simple, ajustez intelligemment, et ne surdimensionnez pas vos modèles.
Le machine learning n’est pas de la magie noire. Comme en cuisine, souvent un bon couteau bien aiguisé vaut mieux qu’un robot à 15 fonctions : il fait le travail plus vite, plus simplement, et vous comprenez vraiment ce que vous faites.
Références
Elineau, Amanda, Corinne Desnos, Laetitia Jalabert, Marion Olivier, Jean-Baptiste Romagnan, Manoela Costa Brandao, Fabien Lombard, et al. 2024. « ZooScanNet: Plankton Images Captured with the ZooScan ». SEANOE. https://doi.org/10.17882/55741.
Maracani, Andrea, Vito Paolo Pastore, Lorenzo Natale, Lorenzo Rosasco, et Francesca Odone. 2023. « In-Domain versus out-of-Domain Transfer Learning in Plankton Image Classification ». Scientific Reports 13 (1): 10443. https://doi.org/10.1038/s41598-023-37627-7.
Picheral, Marc, Lucas Courchet, Laetitia Jalabert, Solène Motreuil, Louis Carray-Counil, Florian Ricour, et Flavien Petit. 2024. « UVP6Net : Plankton Images Captured with the UVP6 ». SEANOE. https://doi.org/10.17882/101948.
Sosik, Heidi M., Emily E. Peacock, et Emily F. Brownlee. 2015. « Annotated Plankton Images Data Set for Developing and Evaluating Classification Methods ». URL http://darchive. mblwhoilibrary. org/handle/1912/7341.