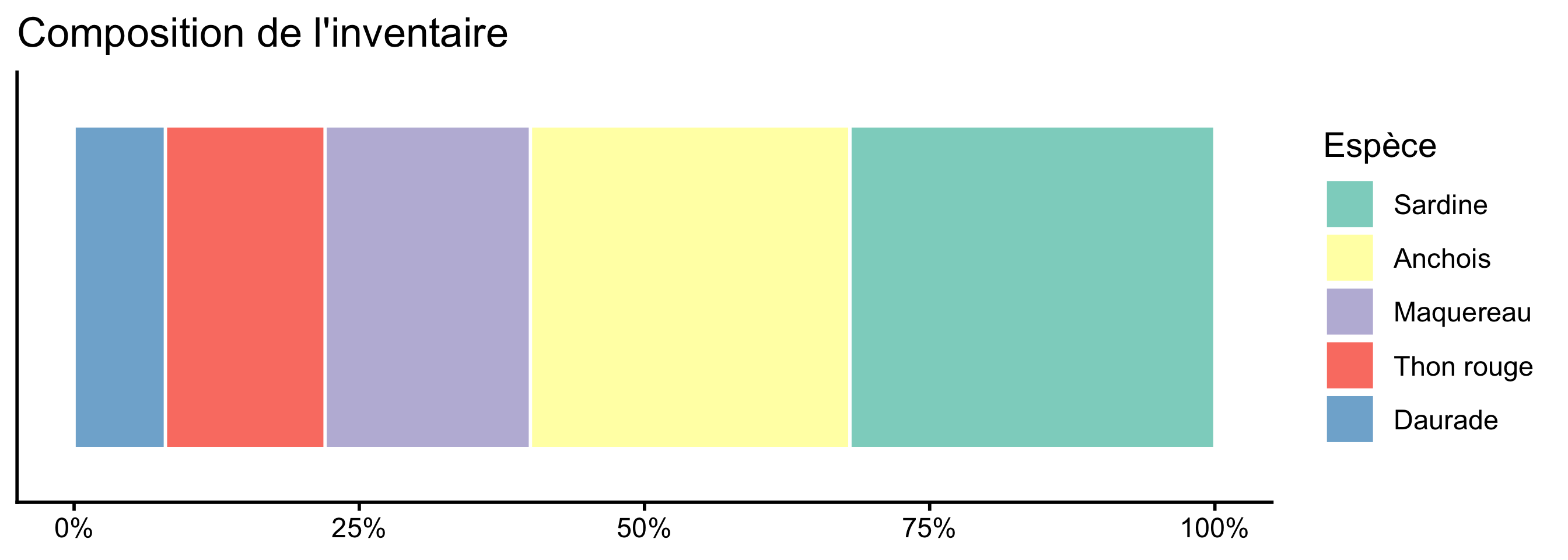Pourquoi le graphique en camembert est (presque) toujours une mauvaise idée
Data viz
Tutoriels R
Le camembert est omniprésent dans les rapports et présentations. Pourtant, c’est l’un des graphiques les moins efficaces qui soit, et le seul qui porte le nom d’un fromage. Voici pourquoi, et quoi utiliser à la place avec ggplot2.
Auteur·rice
Thelma Panaïotis
Date de publication
26 mars 2026
Mots clés
dataviz, ggplot2, camembert, pie chart, barplot, visualisation de données, R, débutant
Pourquoi le graphique en camembert est (presque) toujours une mauvaise idée
Un classique du mauvais choix de visualisation, et comment y remédier avec ggplot2.
Le camembert : un graphique trop populaire pour son propre bien
Ouvrez le premier rapport PowerPoint venu, et vous en trouverez un. Le camembert (pie chart en anglais) est partout : dans les bilans annuels, les sondages, les dashboards d’entreprise. Il est intuitif à créer, familier pour le lecteur, et donne l’impression de synthétiser une information complexe en un coup d’œil.
Pourtant, les spécialistes de la visualisation de données le déconseillent quasi-unanimement. Pourquoi ? Parce que notre cerveau est particulièrement mauvais pour comparer des surfaces et des angles. Et c’est précisément ce que le camembert lui demande de faire.
Ce que cet article ne dit pas
Il n’existe quasiment aucun cas où un camembert est le meilleur choix possible. Mais s’il est déjà dans votre rapport et que vous n’avez pas le temps de le refaire, le monde ne s’arrêtera pas. L’objectif ici, c’est de comprendre pourquoi il peut poser problème, et d’avoir les outils pour faire mieux.
Notre cerveau aime les longueurs, pas les angles
En dataviz, on distingue plusieurs encodages visuels : les façons dont on représente une valeur numérique. Voici les principaux, du plus précis au moins précis pour la perception humaine :
Position sur un axe commun → très précis
Longueur → précis
Surface → approximatif
Angle → approximatif
Couleur / teinte → approximatif
Le graphique en barres utilise la longueur et la position sur un axe. Le camembert, lui, utilise l’angle (et la surface des portions). On lui demande donc d’exploiter deux des encodages les moins précis qui soient.
La conséquence est immédiate : il est très difficile de distinguer deux portions proches, et quasi-impossible de comparer des portions non adjacentes.
Un exemple concret
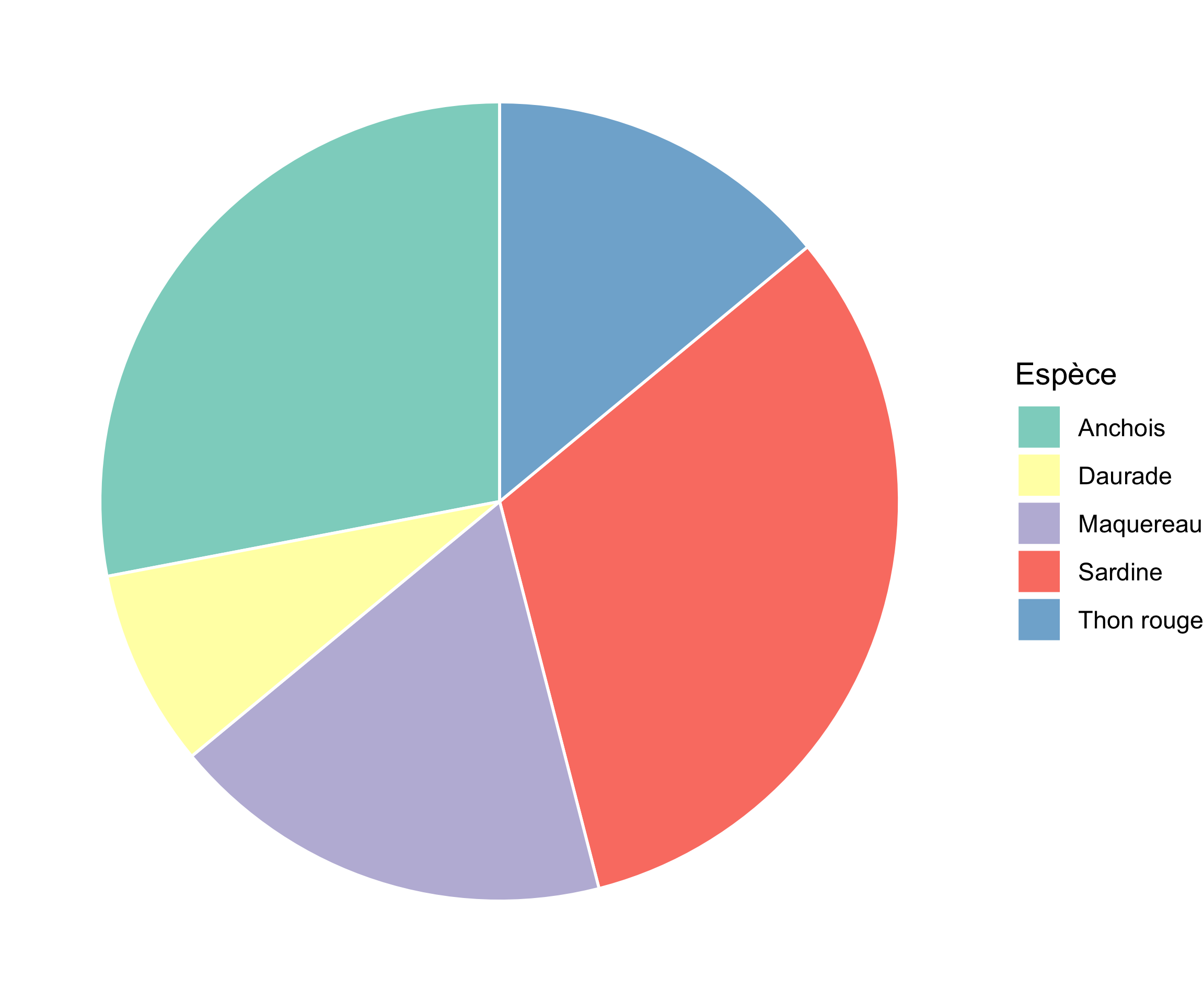
Prenons des données fictives : la répartition de cinq espèces dans un inventaire marin.
Voici ce que donne un camembert avec ggplot2.
ggplot(especes, aes(x ="", y = proportion, fill = espece)) +geom_col(width =1, color ="white") +coord_polar(theta ="y") +scale_fill_brewer(palette ="Set3") +labs(fill ="Espèce", x =NULL, y =NULL) +theme_void() +theme(legend.position ="right")
Figure 1: Répartition de 5 espèces, version camembert
Maintenant, répondez sans regarder les valeurs : quelle différence y a-t-il entre Sardine et Anchois ? Entre Thon rouge et Daurade ? Difficile à dire, n’est-ce pas, et pourtant les différences sont réelles (32% vs 28%, et 14% vs 8%).
Testez votre perception
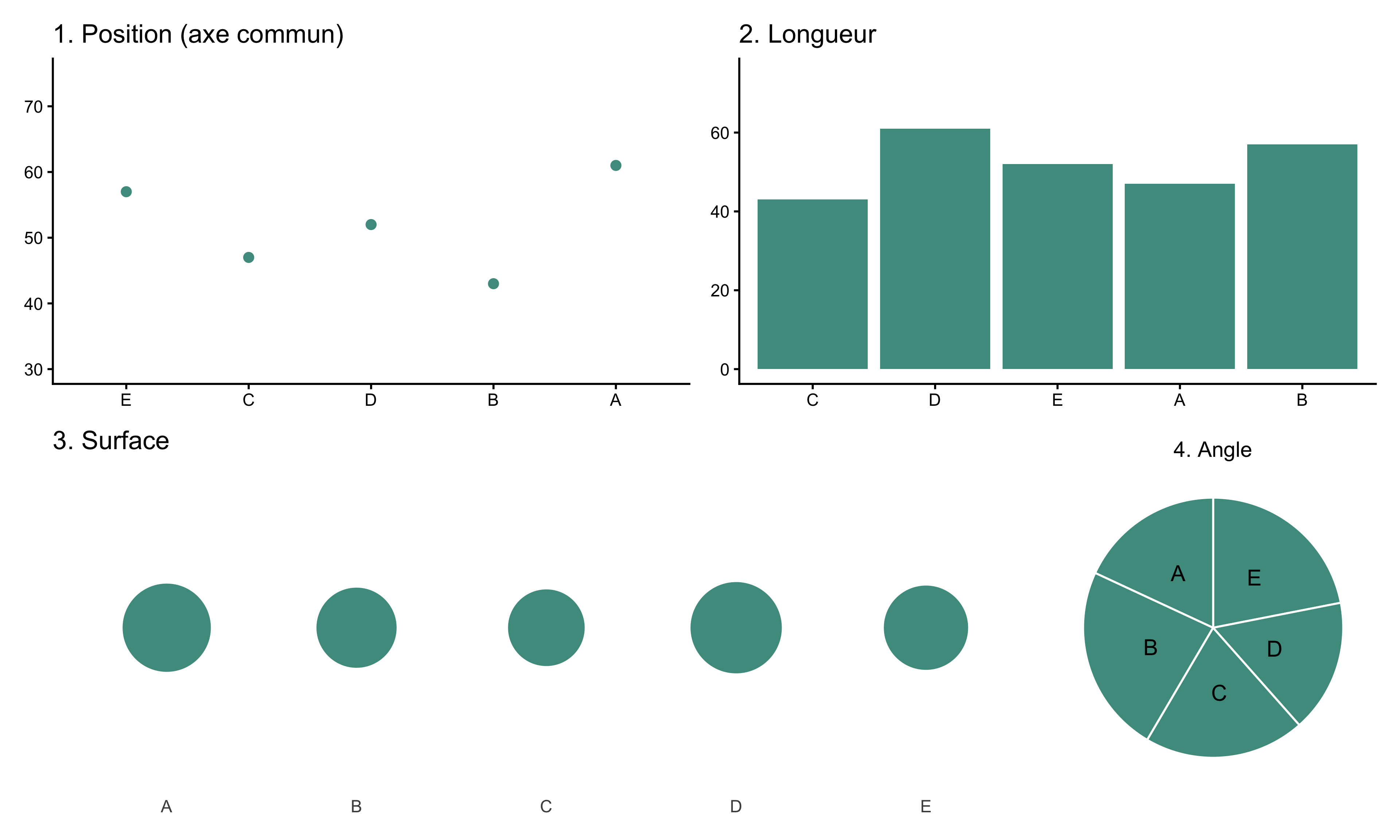
Les quatre graphiques ci-dessous représentent chacun un ensemble de cinq valeurs comprises entre 43 et 61, sans valeur qui se démarque franchement. Dans chaque graphique, les lettres A à E sont réassignées indépendamment : A n’est pas la même valeur d’un graphique à l’autre. Pour chacun, essayez de classer les lettres du plus grand au plus petit avant de regarder la réponse.
Figure 2: Les mêmes cinq valeurs, quatre encodages différents, mais les lettres sont réassignées dans chaque graphique. Pour chacun, classez du plus grand au plus petit.
AstuceRéponse
Les valeurs de référence, du plus grand au plus petit : 61 > 57 > 52 > 47 > 43.
Position : A > E > D > C > B
Longueur : D > B > E > A > C
Surface : D > A > E > B > C
Angle : B > E > C > A > D
Trois problèmes concrets du camembert
1. Comparer des portions adjacentes est difficile
Deux parts de tailles proches se ressemblent visuellement, même si les valeurs diffèrent de plusieurs points. Notre œil ne distingue pas facilement 28% d’un 32% dans un angle.
2. Comparer des portions non adjacentes est encore plus difficile
Si les portions Anchois et Thon rouge ne sont pas côte à côte, les comparer devient un exercice mental : il faut mentalement “déplacer” les portions pour les superposer. Avec un graphique en barres, c’est immédiat.
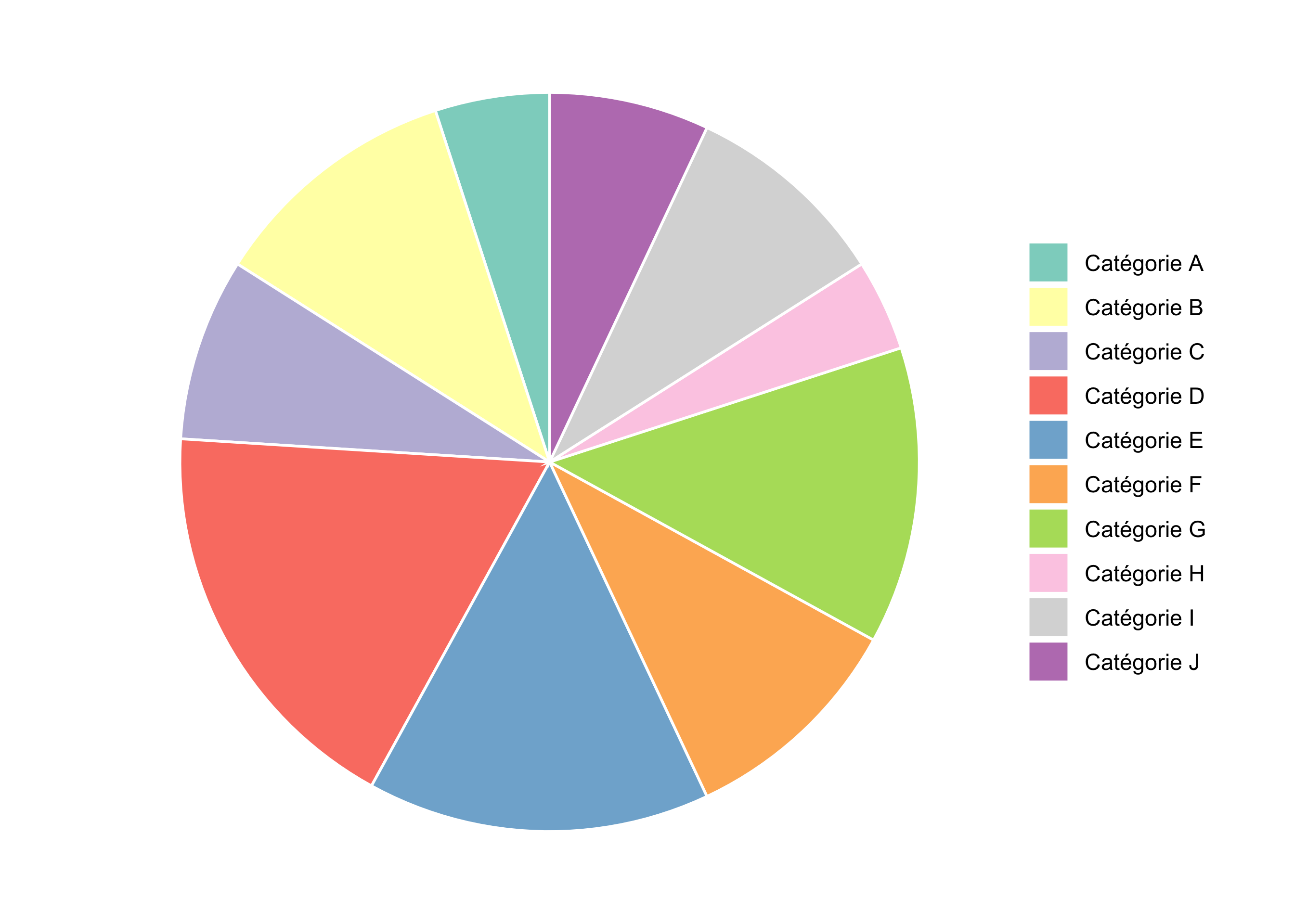
3. Les camemberts avec beaucoup de catégories sont illisibles
set.seed(1)
# 10 catégories fictivesbeaucoup <-tibble(categorie =paste("Catégorie", LETTERS[1:10]),valeur =sample(c(18, 15, 13, 11, 10, 9, 8, 7, 5, 4)))ggplot(beaucoup, aes(x ="", y = valeur, fill = categorie)) +geom_col(width =1, color ="white") +coord_polar(theta ="y") +scale_fill_brewer(palette ="Set3") +labs(fill =NULL, x =NULL, y =NULL) +theme_void() +theme(legend.position ="right")
Figure 3: Un camembert avec 10 catégories, très difficile à lire
Dès que l’on dépasse 4 ou 5 catégories, et a fortiori quand les valeurs ne sont pas ordonnées, le camembert devient un puzzle coloré sans grande valeur informative.
Quand le camembert est (à peu près) acceptable
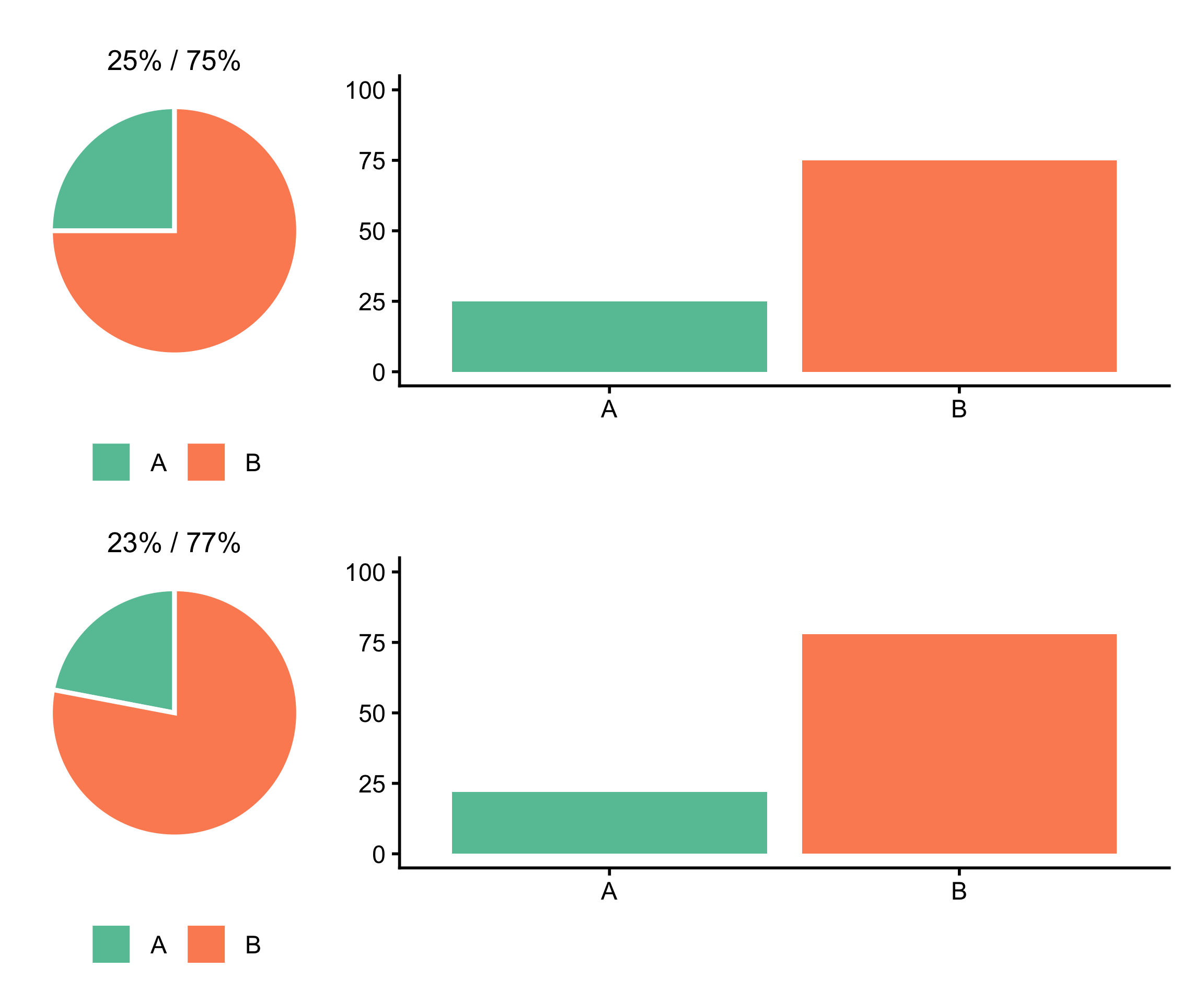
Le camembert a une vraie qualité (en dehors d’être délicieux sous sa forme fromagère) souvent ignorée : notre système visuel est particulièrement sensible aux repères angulaires canoniques : les lignes horizontales, verticales et les angles droits. Sur un camembert, cela se traduit par une capacité à détecter facilement si une part franchit le seuil des 50% (la ligne de séparation coupe le cercle en deux moitiés égales) ou des 25% (angle droit, un quart du disque).
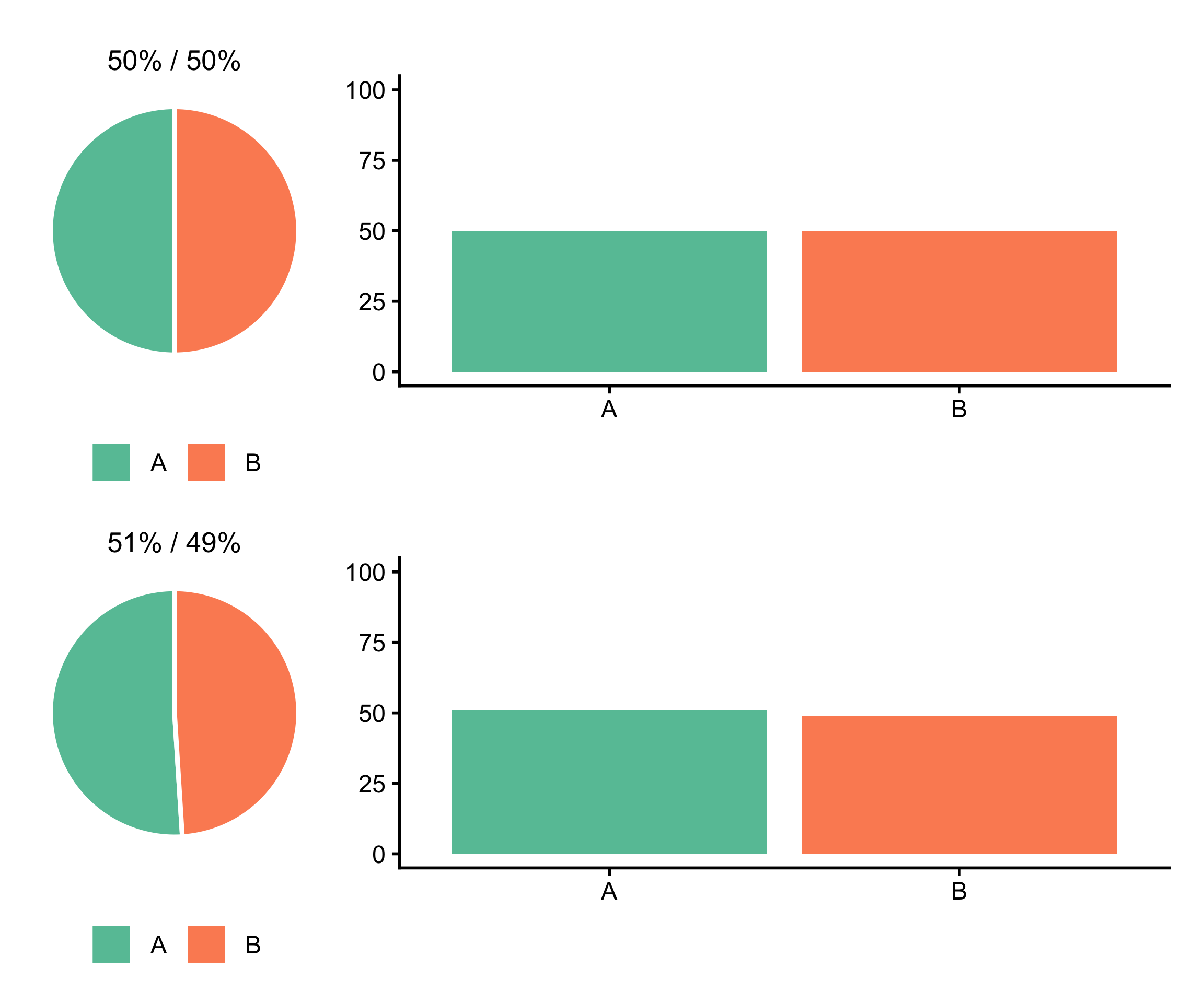
Dans ces cas précis, le camembert peut même battre le graphique en barres. Regardons ça sur un exemple.
Figure 4: Autour de 50%, sur le camembert, le franchissement du seuil se détecte visuellement même à 51/49. Sur les barres, les deux rectangles sont quasi-identiques.
À exactement 50%, les deux graphiques sont lisibles. À 51/49 en revanche, la ligne de partage dépasse légèrement le centre sur le camembert : on détecte immédiatement qu’un camp a franchi la majorité. Sur les barres, les deux rectangles sont devenus quasi-identiques sans lire les valeurs.
Le même phénomène se produit autour de 25%, grâce à la reconnaissance de l’angle droit. Même à 23%, on perçoit intuitivement “environ un quart” grâce au repère de l’angle droit. Sur les barres, cette intuition est moins immédiate.
Figure 5: Autour de 25%, l’angle droit sert de repère mental, pas de valeur exacte à atteindre. À 23%, on reconnaît encore clairement ‘environ un quart’ sur le camembert.
À 25%, l’angle droit est parfaitement reconnaissable. À 23%, le repère mental “un quart” reste lisible sur le camembert, alors que les barres donnent surtout l’impression de deux rectangles de hauteurs différentes, sans ancrage intuitif.
Règle pratique
Le camembert est justifié si :
vous avez 2 à 3 catégories maximum
votre message est centré sur le franchissement d’un seuil à 50%, 25% ou 75%
les valeurs tombent vraiment proches de ces repères.
Dans tous les autres cas, les barres restent plus efficaces.
On sait maintenant quand éviter le camembert, et les rares cas où il se justifie. Reste à savoir par quoi le remplacer.
Ce qu’il faut utiliser à la place
Le graphique en barres : simple, efficace, toujours juste
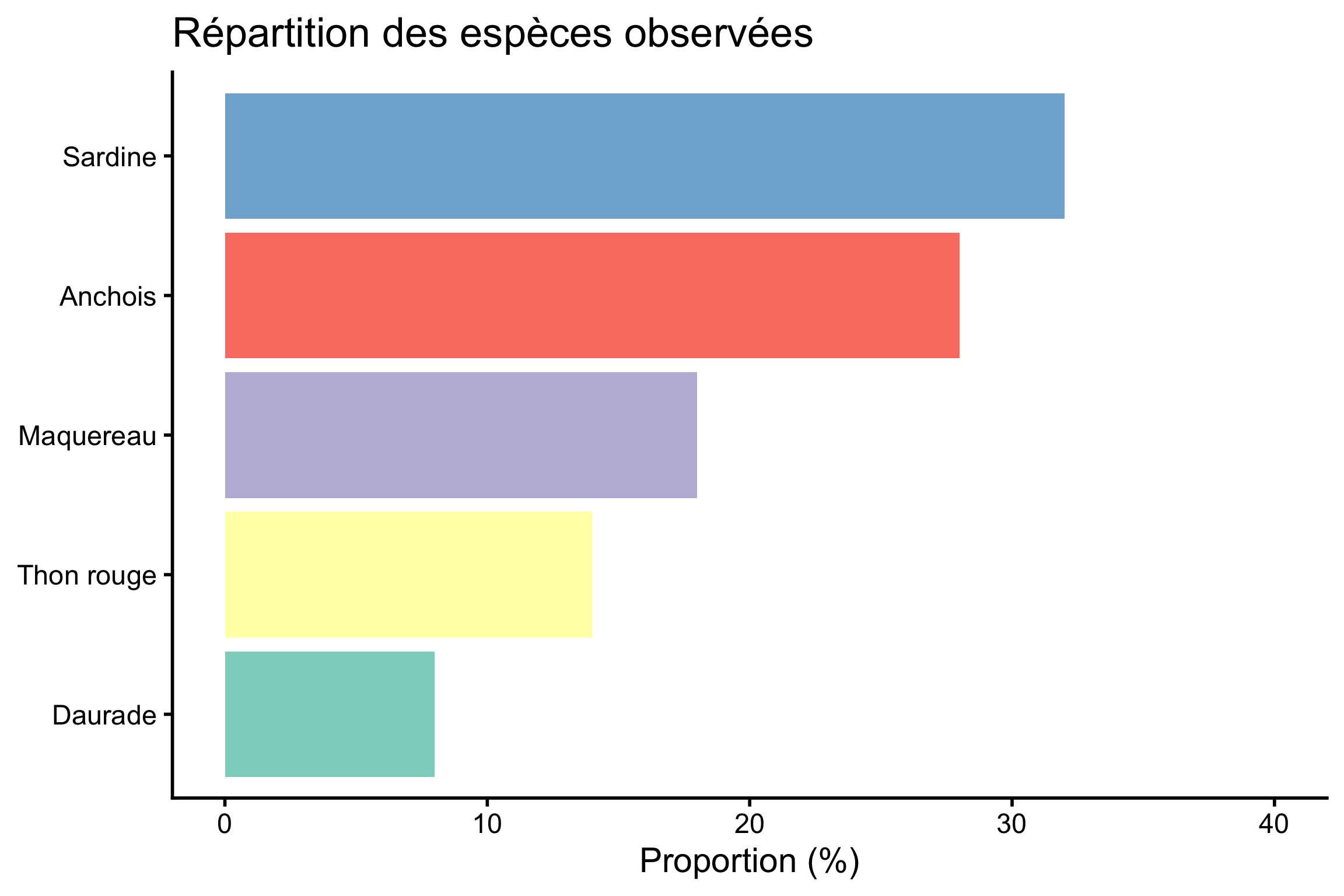
Le graphique en barres (geom_col() ou geom_bar() dans ggplot2) utilise la longueur comme encodage, l’un des plus précis pour notre perception. Reprenons nos données d’espèces :
especes |>mutate(espece =fct_reorder(espece, proportion)) |># Tri par valeurggplot(aes(x = proportion, y = espece, fill = espece)) +geom_col(show.legend =FALSE) +scale_fill_brewer(palette ="Set3") +scale_x_continuous(limits =c(0, 40)) +labs(x ="Proportion (%)", y =NULL, title ="Répartition des espèces observées") +theme_classic()
Figure 6: Les mêmes données, version barres triées
Avec ce graphique, la hiérarchie est immédiate : Sardine > Anchois > Maquereau > Thon rouge > Daurade. Les différences entre catégories sont lisibles d’un coup d’œil.
Astuce fct_reorder()
Trier les barres par valeur (plutôt que par ordre alphabétique) est presque toujours une bonne idée. Cela met en évidence la hiérarchie naturelle des données. On utilise fct_reorder() du package forcats (inclus dans le tidyverse) pour ça.
Et si je veux vraiment montrer des proportions ?
Si votre message est vraiment centré sur les proportions (par exemple, montrer qu’une catégorie représente “les deux tiers du total”), le graphique en barres empilées à 100% est une alternative honnête :
especes |>mutate(espece =fct_reorder(espece, proportion, .desc =TRUE)) |>ggplot(aes(x = proportion, y ="Composition", fill = espece)) +geom_col(position ="fill", color ="white") +scale_x_continuous(labels = scales::percent) +scale_fill_brewer(palette ="Set3") +labs(x =NULL, y =NULL, fill ="Espèce", title ="Composition de l'inventaire") +theme_classic() +theme(axis.text.y =element_blank(), axis.ticks.y =element_blank(), panel.grid =element_blank() )
Figure 7: Barres empilées à 100%, une alternative aux camemberts
C’est plus lisible qu’un camembert et on conserve l’idée de “parts d’un tout”.
Et le donut chart dans tout ça ?
Le donut chart, c’est un camembert avec un trou au milieu : Homer Simpson approuverait la forme, pas forcément le contenu. Il souffre des mêmes limites de perception, avec un avantage : on peut glisser un chiffre clé au centre, ce qui peut avoir du sens dans un dashboard. En dehors de ce cas, les barres font mieux. Et contrairement au vrai donut, pas de glaçage pour se consoler.
Récapitulatif : quand utiliser quoi ?
Situation
Graphique recommandé
Comparer des catégories entre elles
Barres triées (geom_col)
Montrer une composition (proportions)
Barres empilées 100%
Montrer une évolution dans le temps
Ligne (geom_line)
Franchir un seuil à 50%, 25% ou 75%
Camembert (si vraiment pile sur le repère)
Le camembert au four avec un filet de miel, en revanche, reste toujours recommandé.
Pour aller plus loin
Cleveland, William S., et Robert McGill. 1984. « Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods ». Journal of the American Statistical Association 79 (387): 531‑54. https://doi.org/10.1080/01621459.1984.10478080.
Skau, Drew, et Robert Kosara. 2016. « Arcs, Angles, or Areas: Individual Data Encodings in Pie and Donut Charts ». Computer Graphics Forum 35 (3): 121‑30. https://doi.org/10.1111/cgf.12888.