Validation croisée : évaluer son modèle sans se mentir
Tutoriels R
Machine Learning
Quand le train/test split ne suffit pas, la cross-validation prend le relais. Principe, implémentation en R et variantes pour une évaluation robuste de vos modèles.
Mots clés
machine learning, cross-validation, validation croisée, k-fold, rsample, tidymodels, R
Validation croisée : évaluer son modèle sans se mentir
Le train/test split ne suffit pas toujours. La cross-validation, si.
Cet article fait suite au tutoriel Train/test split : séparer ses données pour le machine learning. Si tu n’es pas encore à l’aise avec le principe de séparation train/test, je te conseille de le lire d’abord.
Le problème du split unique
Dans un tutoriel précédent, on a vu pourquoi il ne faut jamais évaluer un modèle sur les données qui ont servi à l’entraîner. La solution : séparer les données en un jeu d’entraînement et un jeu de test, entraîner le modèle sur le premier, évaluer sur le second.
C’est un bon point de départ. Mais sur les petits jeux de données, cette approche révèle un défaut gênant : le score obtenu dépend du split choisi.
Pour l’illustrer, on va travailler sur le jeu de données Sonar du package mlbench. Il contient 208 enregistrements sonar collectés en milieu marin : l’objectif est de distinguer les roches (R) des mines sous-marines (M) à partir de 60 variables acoustiques. Une tâche difficile, avec peu de données : le cadre idéal pour mettre en évidence le problème.
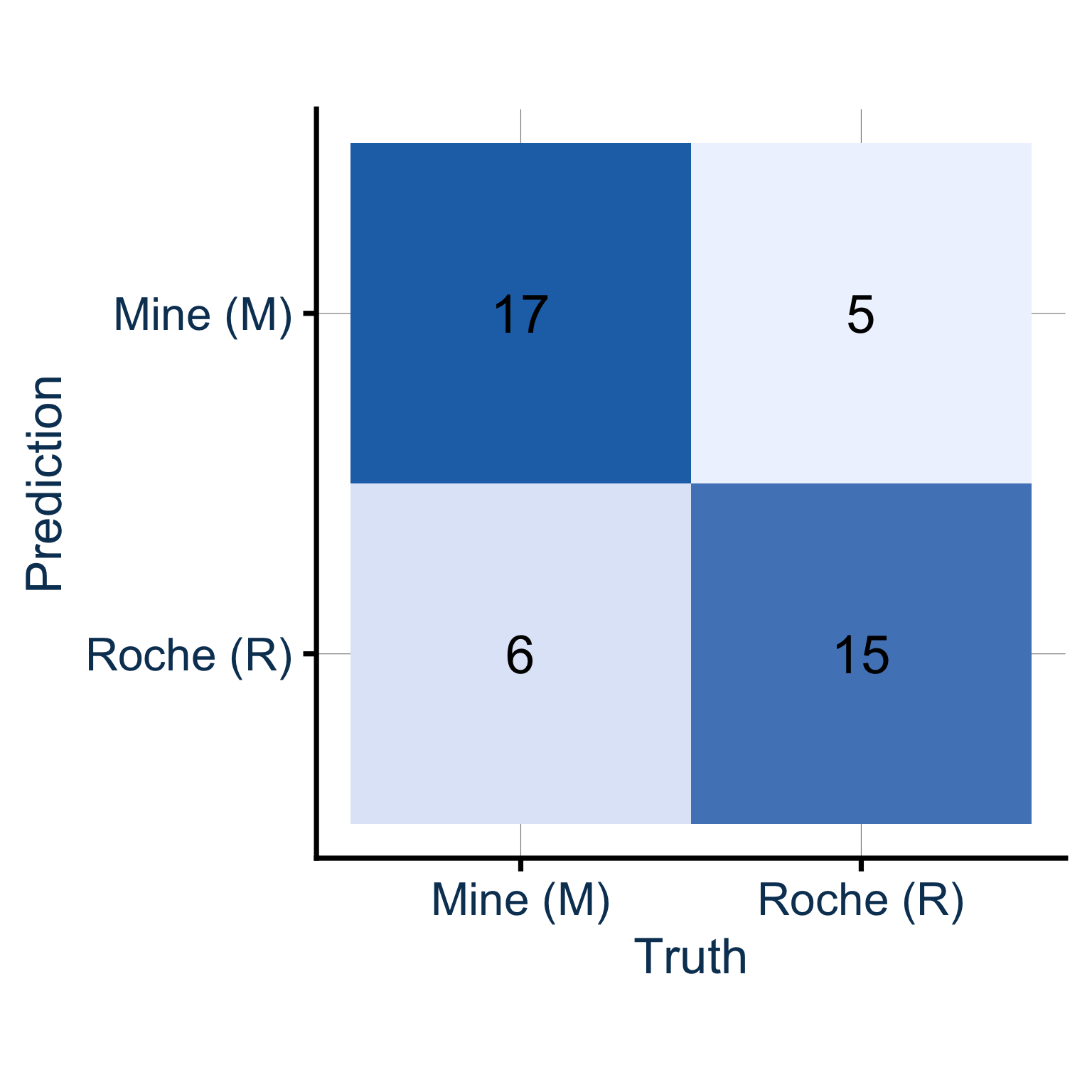
On entraîne un arbre de décision avec un split 80/20 stratifié. Premier essai :
accuracy : 74.4%
Pas mal ! Le lendemain, on rouvre le script et on relance. Résultat :
accuracy : 62.8%
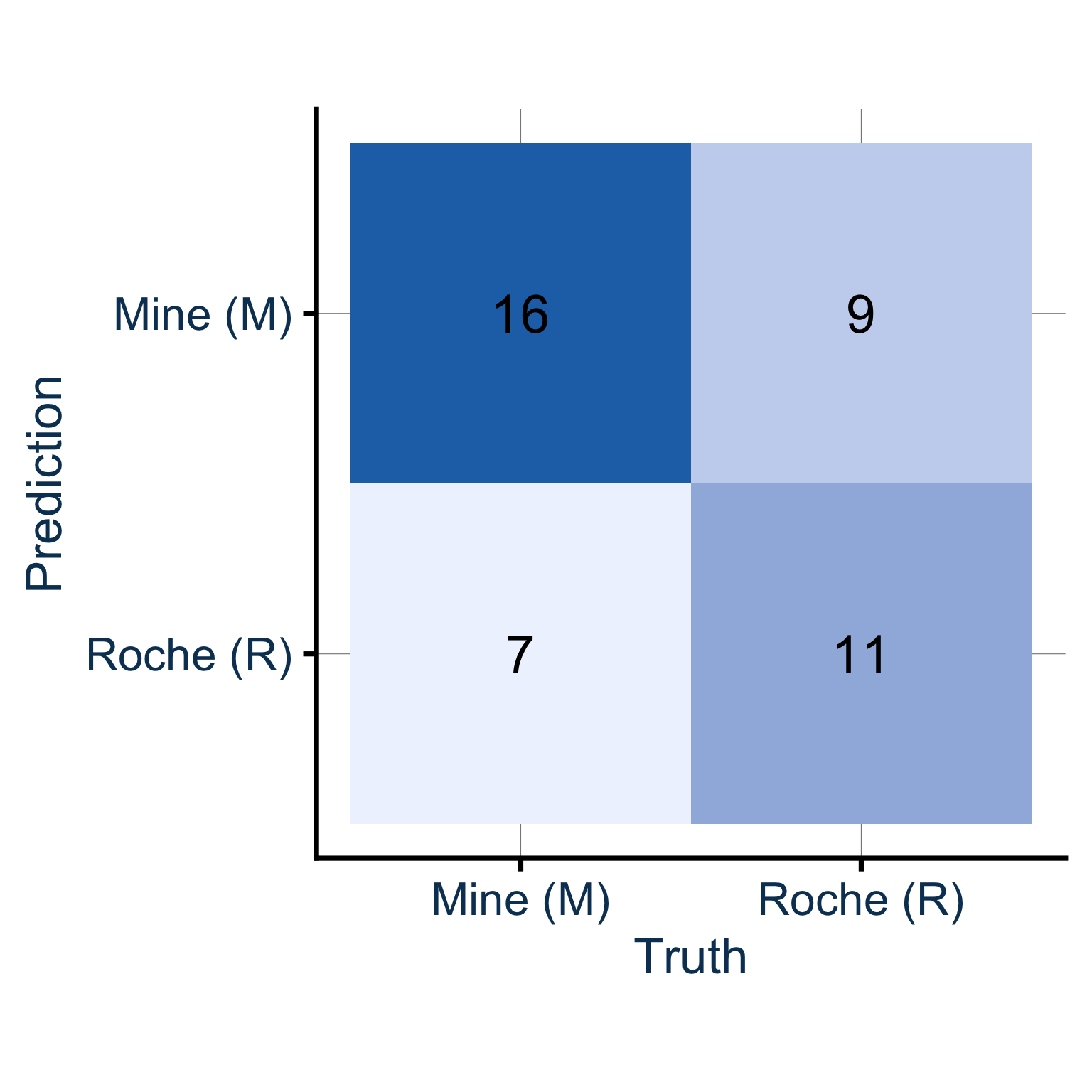
Aïe. Même modèle, mêmes données. Et pourtant, l’accuracy chute de 74.4% à 62.8%. Comment expliquer cette différence ?
Le coupable : le hasard du tirage. À chaque fois qu’on exécute initial_split() sans précaution, les observations sont réparties aléatoirement entre train et test. On ne tombe pas sur le même split d’une exécution à l’autre. C’est là qu’intervient set.seed() : fixer le seed garantit que le tirage sera identique à chaque exécution, et donc que les résultats sont reproductibles.
Mais même avec un seed fixé, le problème de fond reste entier : le score dépend du split choisi. Pour s’en convaincre, répétons l’opération avec 10 seeds différents :
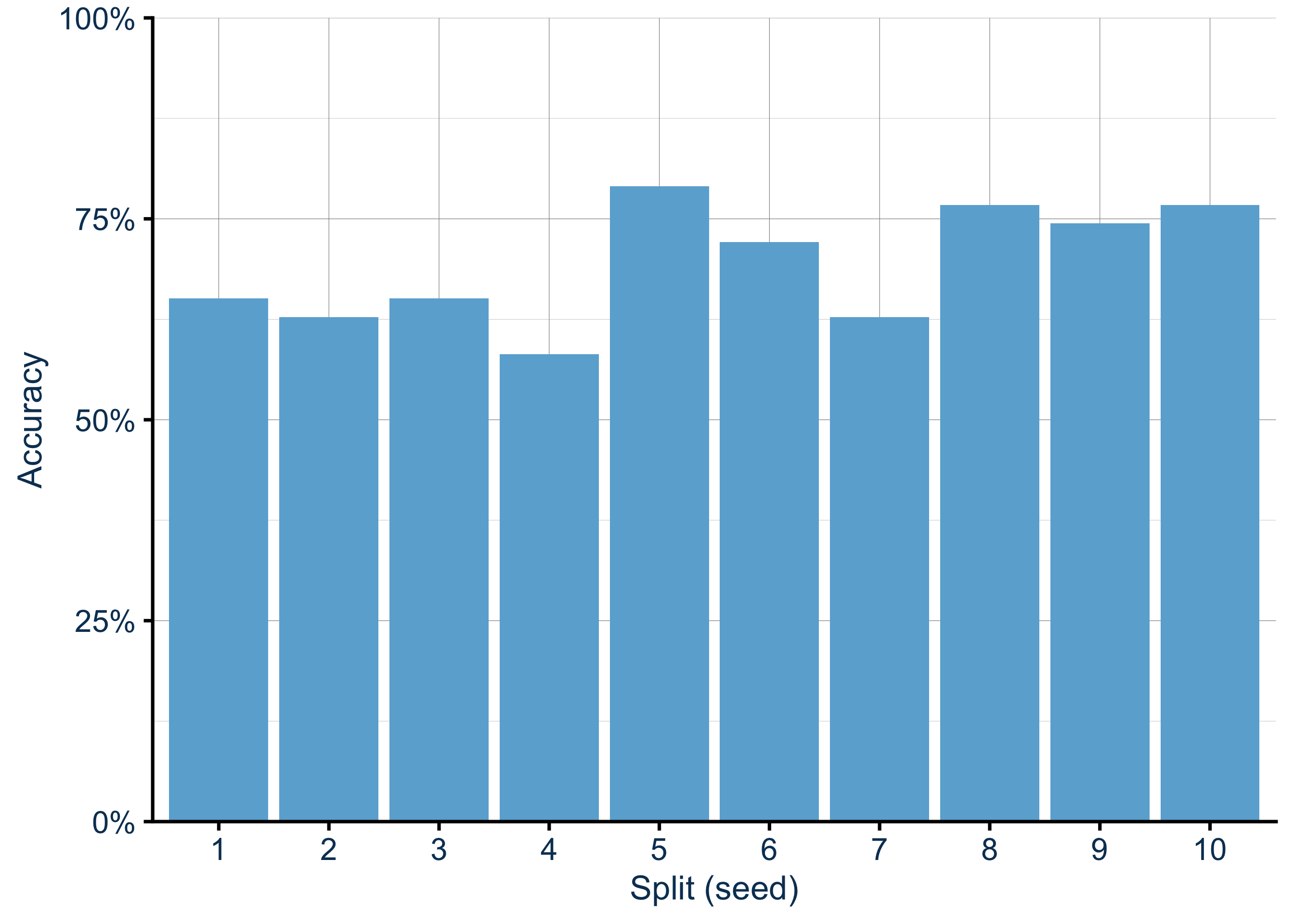
Avec seulement ~40 observations en test, il suffit que quelques cas difficiles tombent du mauvais côté pour faire basculer le score. Et c’est là qu’on se retrouve face à un dilemme :
Le dilemme du petit jeu de données
Augmenter la proportion de test stabilise l’estimation, mais réduit les données d’entraînement et dégrade le modèle. Réduire la proportion de test améliore l’entraînement, mais rend l’évaluation instable. Sur un petit jeu, on ne peut pas gagner sur les deux tableaux à la fois.
La validation croisée sort de cette impasse. Au lieu d’un seul découpage, elle en réalise plusieurs, entraîne le modèle à chaque fois, et agrège les résultats. On obtient une estimation stable, sans sacrifier de données d’entraînement.
La k-fold cross-validation avec rsample
Le principe
Au lieu d’un seul split, on découpe les données en k sous-ensembles de taille égale, appelés folds. À chaque itération, un fold différent joue le rôle de jeu de test, et les k-1 autres servent à l’entraînement. On entraîne donc k modèles, et on obtient k scores qu’on agrège ensuite.
Naviguez entre les itérations pour voir comment les folds se succèdent. Chaque carré représente une observation.
L’avantage clé : à la fin des k itérations, chaque observation a servi exactement une fois comme donnée de test. On ne gaspille rien, et l’estimation des performances n’est plus tributaire d’un seul tirage.
À quoi sert la CV exactement ?
La validation croisée est avant tout un outil d’évaluation : elle fournit une estimation fiable de la capacité de généralisation d’un modèle. Une fois l’évaluation terminée, deux approches sont possibles pour prédire de nouvelles données : réentraîner un unique modèle sur toutes les données disponibles (le plus courant), ou moyenner les prédictions des k modèles pour plus de robustesse.
Implémenter la CV avec vfold_cv() et fit_resamples()
Avec rsample, on crée les folds avec vfold_cv(). Comme pour le train/test split, on stratifie sur la variable cible.
# 5 folds stratifiés
set.seed(2025)
folds <- vfold_cv(Sonar, v = 5, strata = Class)
# Définition du modèle
modele <- decision_tree() |>
set_engine("rpart") |>
set_mode("classification")
# fit_resamples() entraîne et évalue sur chaque fold automatiquement
resultats_cv <- fit_resamples(
modele,
Class ~ .,
resamples = folds,
metrics = metric_set(accuracy)
)
# Score moyen et erreur standard sur les 5 folds
collect_metrics(resultats_cv)# A tibble: 1 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 accuracy binary 0.731 5 0.0329 pre0_mod0_post0collect_metrics() retourne la moyenne des scores sur les k folds et l’erreur standard (std_err), qui quantifie la précision de cette estimation : plus elle est faible, plus la moyenne est fiable.
ImportantCV sur le dataset complet
Dans cet exemple, on applique la CV directement sur Sonar en entier : il n’y a pas de test set mis de côté dès le début. C’est suffisant pour évaluer la capacité de généralisation. Mais quand on veut aussi optimiser des hyperparamètres, on applique la CV uniquement sur le jeu d’entraînement et on réserve le test set pour l’évaluation finale. C’est ce qu’on verra dans le prochain tutoriel sur le tuning.
Combien de folds ?
Les valeurs usuelles sont v = 5 ou v = 10. Avec k = 5, chaque modèle est entraîné sur 80% des données et évalué sur 20% : un bon compromis entre temps de calcul et précision de l’estimation. On passe à v = 10 quand on veut serrer l’estimation au maximum et qu’on a le temps de calcul.
Variantes pour aller plus loin
La k-fold répétée
La repeated k-fold cross-validation consiste à répéter la k-fold plusieurs fois avec des découpages aléatoires différents. Par exemple, une 5-fold répétée 3 fois produit 15 évaluations (5 folds × 3 répétitions) dont on agrège les scores. L’intérêt : réduire encore la variance de l’estimation, surtout sur les petits jeux de données. Le coût : multiplier le temps de calcul par le nombre de répétitions. Dans rsample, il suffit d’ajouter l’argument repeats à vfold_cv().
Le Leave-One-Out
Dans cette variante extrême, chaque observation constitue à son tour le jeu de test : on entraîne autant de modèles qu’il y a d’observations. L’estimation est quasi sans biais, mais le coût computationnel est prohibitif dès que le jeu dépasse quelques centaines d’observations. À réserver aux très petits jeux de données, et peu utilisé en pratique.
CV spatiale et temporelle
Si vos données ont une structure spatiale ou temporelle, un découpage aléatoire en folds introduit une fuite d’information, exactement comme pour le train/test split. Les packages spatialsample et rsample proposent des variantes adaptées : spatial_clustering_cv() pour les données géolocalisées, sliding_window() pour les séries temporelles. Le principe reste le même, seule la façon de construire les folds change.
Et ensuite : le tuning des hyperparamètres
La validation croisée est aussi le cadre standard pour optimiser les hyperparamètres d’un modèle : plutôt que d’évaluer un seul modèle, on évalue toute une série de configurations et on retient la meilleure. C’est ce qu’on appelle le grid search avec CV. C’est précisément l’objet d’un prochain tutoriel.
Envie d’aller plus loin ?
La validation croisée, le tuning des hyperparamètres, les forêts aléatoires, le boosting, les réseaux de neurones… Tout le pipeline, de la séparation des données aux architectures avancées, on le fait ensemble en R pendant 5 jours intensifs et 100% pratiques dans ma formation Machine Learning avec R.