head(sportifs)# A tibble: 6 × 3
heures experience score
<dbl> <dbl> <dbl>
1 7.31 6.00 144.
2 10.6 4.19 180.
3 14.8 4.65 203.
4 6.61 4.36 116.
5 9.76 6.69 194.
6 10.4 5.97 218.machine learning, hyperparamètres, grid search, tuning, arbre de décision, CART, rpart, R
Paramètres, hyperparamètres, grid search : comment faire les bons choix avant d’entraîner son modèle.
Cet article fait suite aux tutoriels Train/test split et Validation croisée. Si ces concepts ne vous sont pas familiers, je vous conseille de les lire d’abord.
À propos du dataset et du modèle utilisés
Le dataset sportifs est simulé, conçu spécialement pour cet article. On a aussi légèrement triché pour que les effets d’un mauvais réglage soient bien visibles : dans la vraie vie, les modèles ont des protections contre cela !
On va travailler sur le dataset sportifs : des données simulées sur 250 athlètes, où l’objectif est de prédire un score de performance à partir du nombre d’heures d’entraînement hebdomadaires et des années d’expérience.
head(sportifs)# A tibble: 6 × 3
heures experience score
<dbl> <dbl> <dbl>
1 7.31 6.00 144.
2 10.6 4.19 180.
3 14.8 4.65 203.
4 6.61 4.36 116.
5 9.76 6.69 194.
6 10.4 5.97 218.Le modèle qu’on va utiliser ici est un arbre de décision. Le principe : pour prédire le score d’un sportif, l’algorithme découpe l’espace des variables prédictives en rectangles, et associe une valeur à chaque zone. À chaque nœud, il choisit la variable et le seuil qui réduisent le mieux l’erreur de prédiction. Ce sont ces règles de coupure que l’arbre apprend à partir des données. Ce sont ses paramètres.
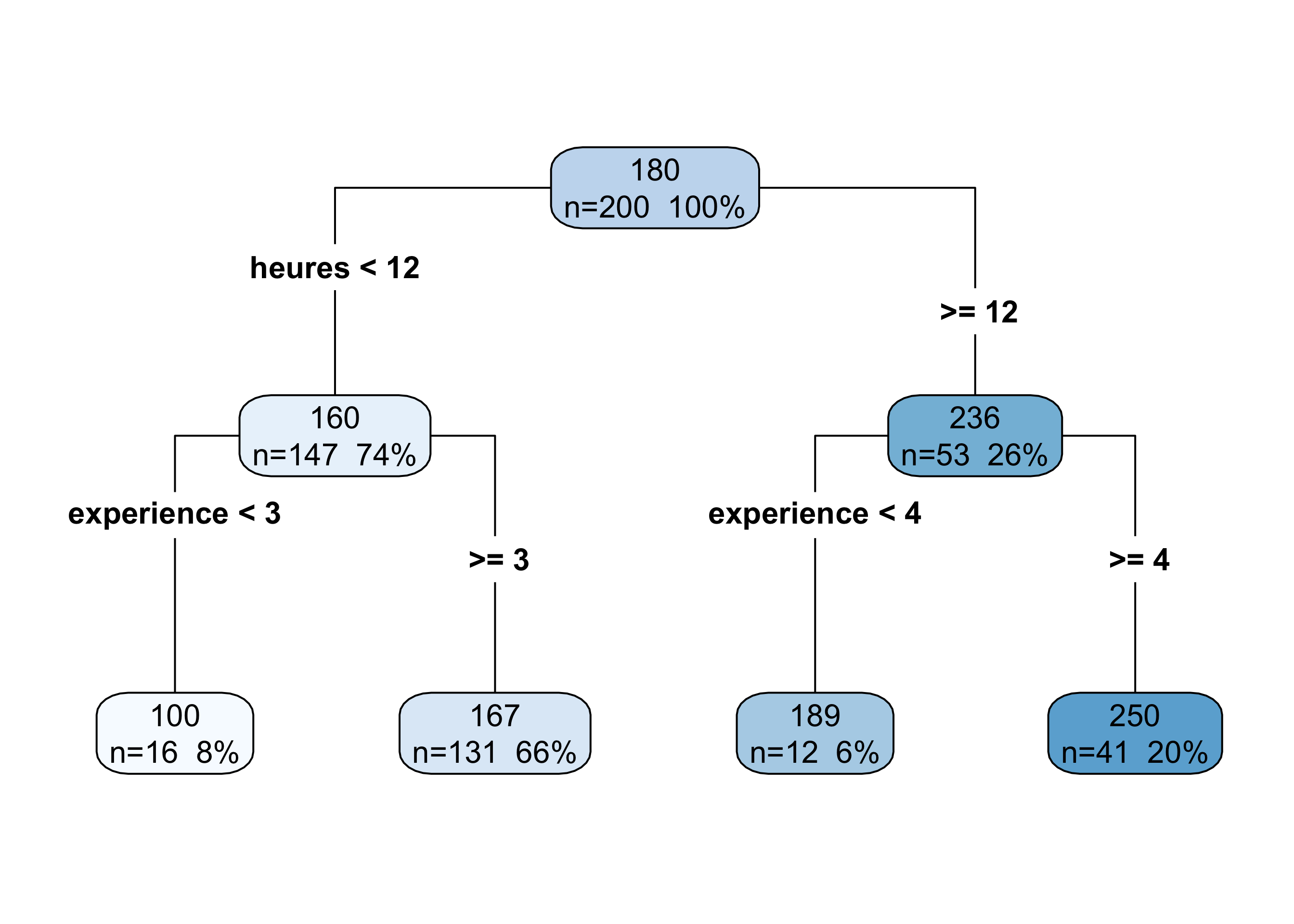
max_depth = 2). Chaque nœud montre la règle de coupure apprise par le modèle : la variable choisie et le seuil optimal.
Ces règles de coupure sont apprises pendant l’entraînement : l’algorithme a testé toutes les valeurs possibles et retenu celles qui minimisent l’erreur. On ne les fixe pas, on les découvre.
En revanche, max_depth (la profondeur maximale de l’arbre) est un réglage qu’on fixe avant l’entraînement. Le modèle ne le choisit pas : c’est notre décision. C’est un hyperparamètre.
Et ce choix a des conséquences importantes. Avec max_depth = 4, l’arbre peut apprendre des règles beaucoup plus fines (Figure 2).
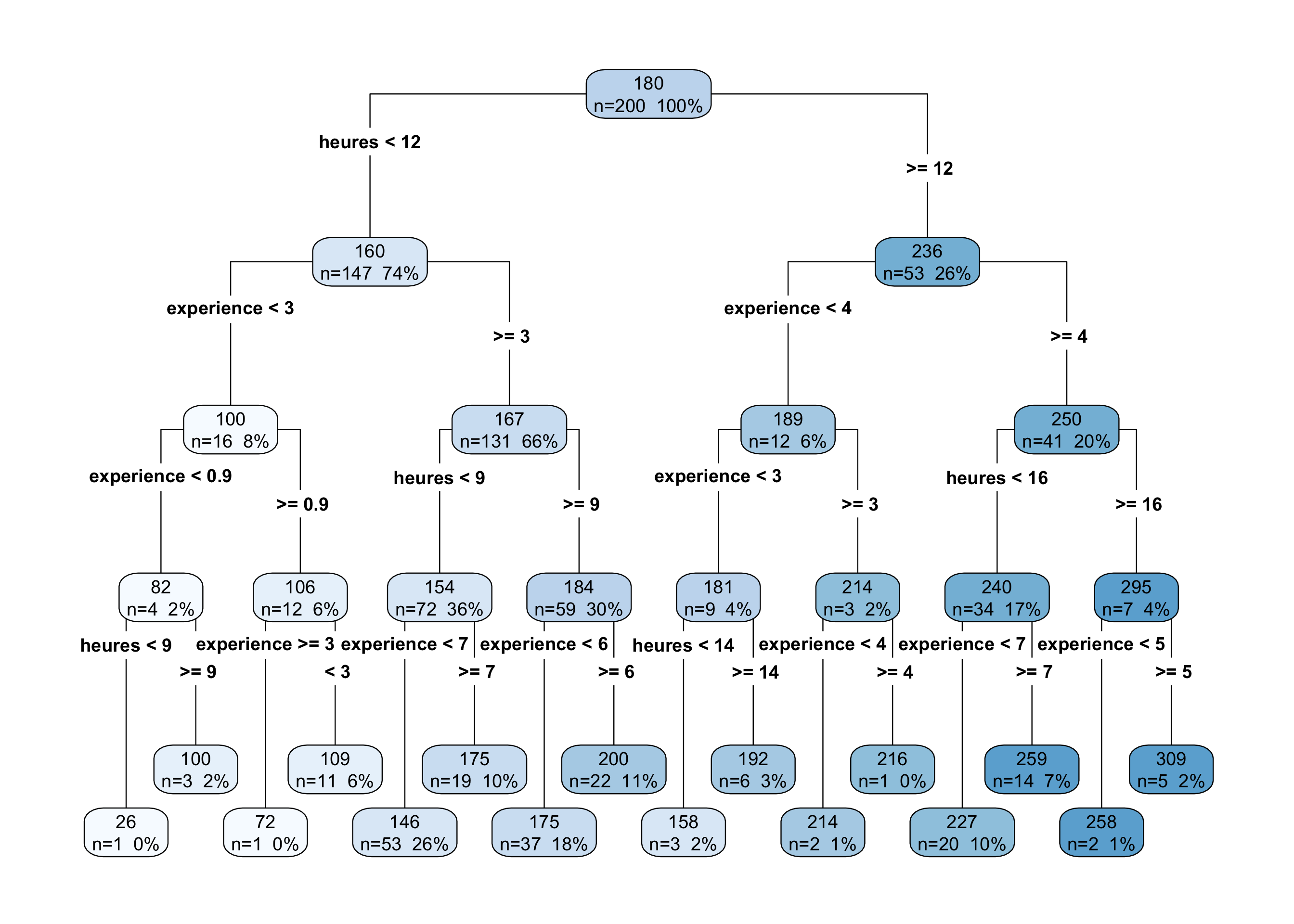
max_depth = 4). L’arbre découpe l’espace en régions très petites pour coller au plus près des données d’entraînement.
Les paramètres sont appris par le modèle pendant l’entraînement : les règles de coupure, les seuils, les valeurs prédites dans chaque feuille.
Les hyperparamètres sont fixés par vous, avant l’entraînement. Pour un arbre de décision, on doit définir sa profondeur maximale (max_depth), mais ce n’est pas le seul hyperparamètre. Le modèle ne les optimise pas : c’est votre rôle.
Mais alors, quelle valeur de max_depth choisir ? Trop faible, le modèle est trop simple et rate des patterns importants. Trop élevée, il mémorise les données d’entraînement et généralise mal. C’est exactement ce qu’on va résoudre.
Le grid search (recherche en grille) fonctionne exactement comme son nom l’indique : on dresse une liste de valeurs candidates, on les teste toutes en validation croisée, et on retient la meilleure. Ni plus, ni moins.
On va tester toutes les valeurs de max_depth de 2 à 20 par pas de 2. Pour chaque valeur, le modèle est entraîné et évalué sur 5 folds de validation croisée. Le score final est la moyenne des 5 évaluations.
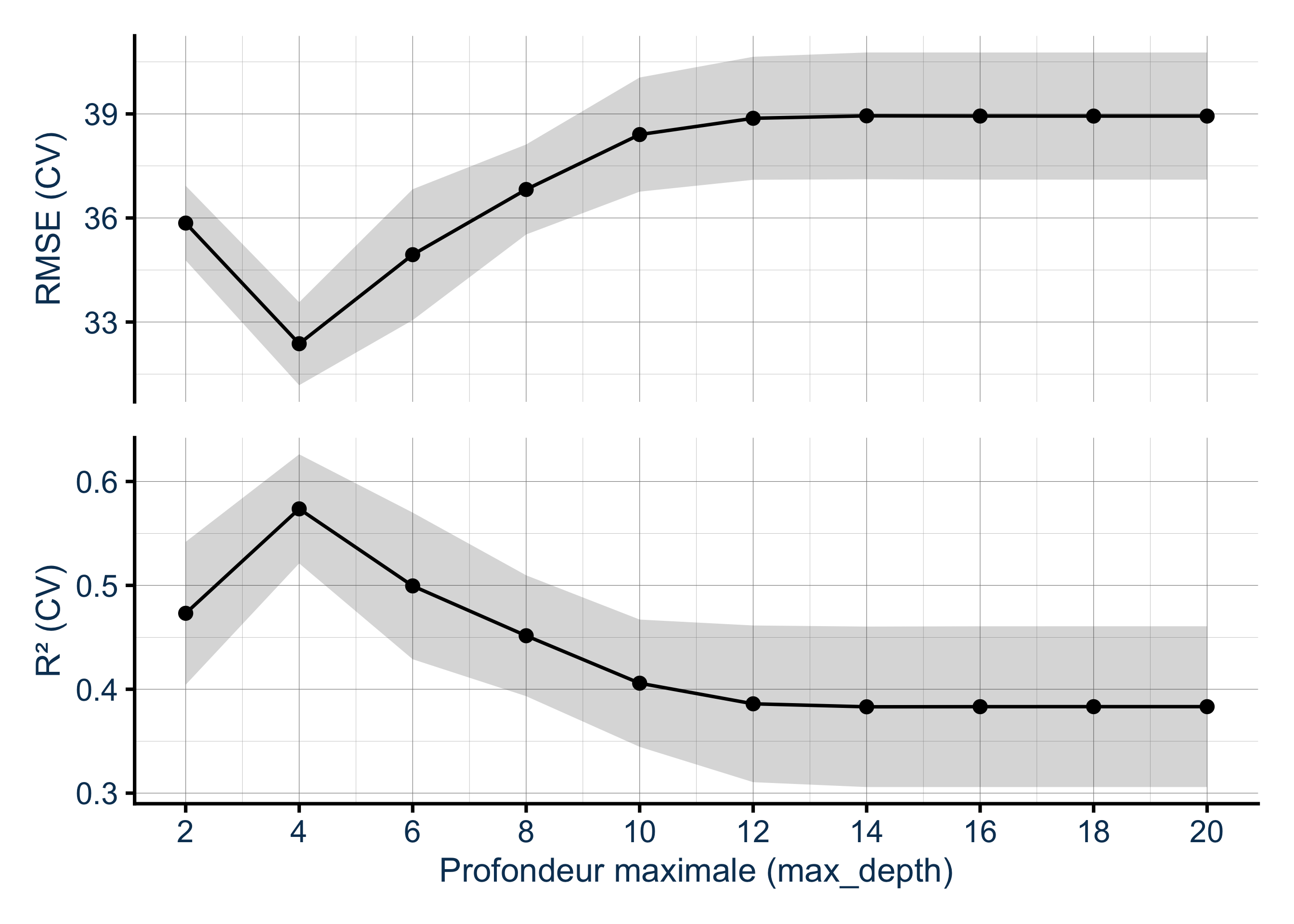
La courbe montre clairement un optimum : en dessous, le modèle est trop rigide pour capturer la relation entre les variables ; au-delà, il s’adapte trop aux données d’entraînement et perd en généralisation. On retient la valeur qui minimise le RMSE, ici max_depth = 4.
Pour rendre ça concret, voici les surfaces de décision pour trois valeurs de max_depth : trop faible, optimale, trop élevée (Figure 5).
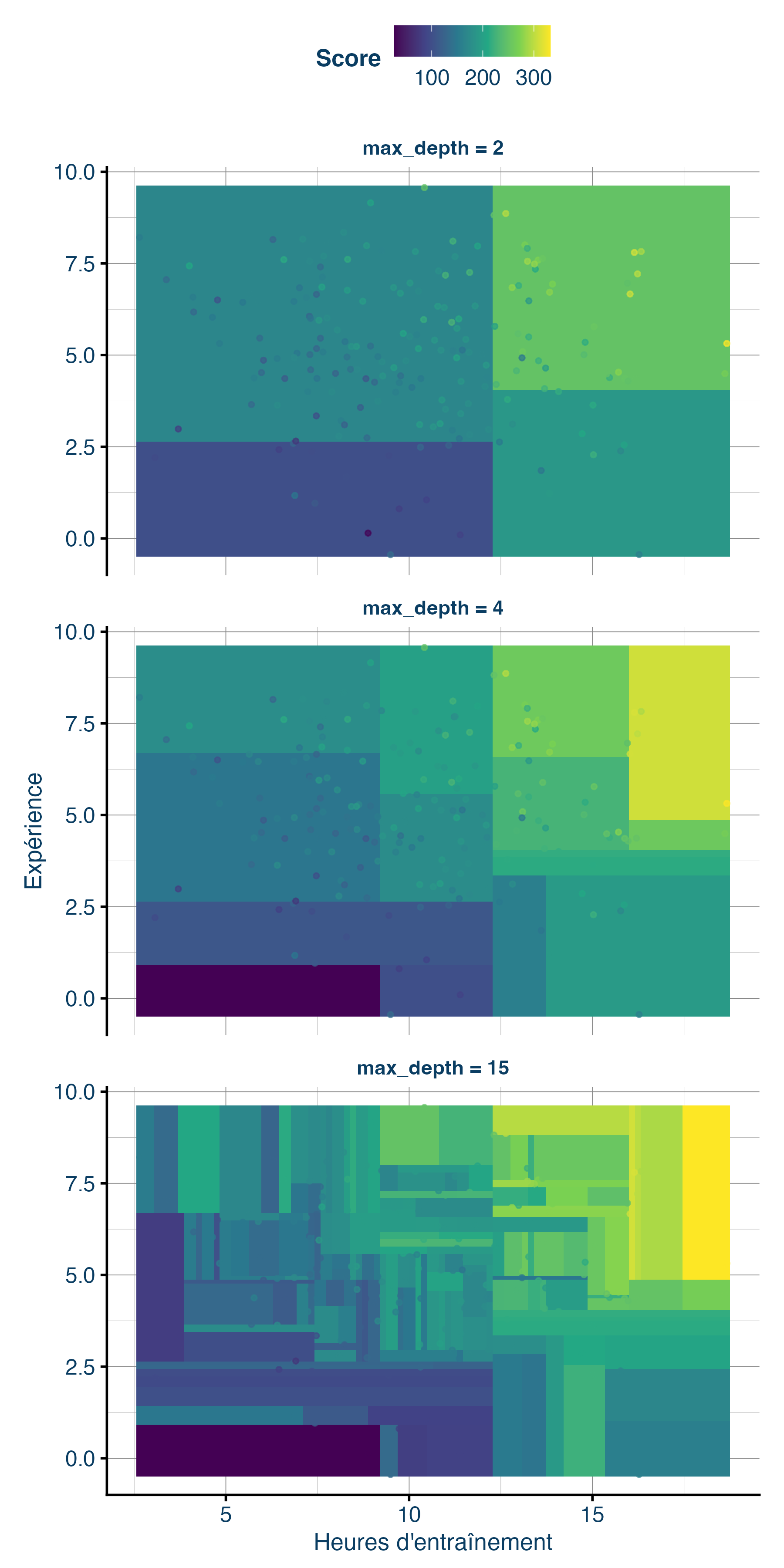
max_depth. En haut, l’arbre est trop simple. Au milieu, il capture bien la structure des données. En bas, il découpe l’espace en cases trop petites et mémorise le bruit.
On entraîne enfin le modèle final avec la profondeur optimale sur l’ensemble du jeu d’entraînement, et on l’évalue une seule fois sur le jeu de test.
Le jeu de test reste intouché pendant tout le grid search. L’utiliser pour choisir max_depth reviendrait à tricher : les performances mesurées seraient trop optimistes.
Le coût computationnel peut grimper vite. Ici on a optimisé un seul hyperparamètre. Dans les faits, il y en a souvent 3 ou 4 à optimiser simultanément. Si on teste 4 valeurs pour 4 hyperparamètres, on se retrouve avec 4⁴ = 256 configurations à tester, sur chaque fold de la CV. Avec 5 folds, cela reviendrait à entraîner 1280 modèles !
Il existe des alternatives au grid search exhaustif. La recherche aléatoire (random search) tire des combinaisons au hasard : souvent presque aussi efficace pour un coût bien moindre. La recherche bayésienne cible intelligemment les zones prometteuses. Ces méthodes, ainsi que d’autres hyperparamètres et modèles bien plus puissants, font partie de ce qu’on explore ensemble dans la formation.
Envie d’aller plus loin ?
Le tuning des hyperparamètres, les forêts aléatoires, le boosting, les réseaux de neurones… Tout le pipeline, de la séparation des données aux architectures avancées, on le fait ensemble en R pendant 5 jours intensifs et 100% pratiques dans la formation Machine Learning avec R.
Comment choisir
max_depth?On pourrait évaluer les performances du modèle sur les données d’entraînement pour choisir
max_depth. Mais c’est comme corriger ses propres copies : le modèle a déjà vu ces données, les résultats seront toujours trop optimistes.Le jeu de test, alors ? Pas non plus. Son rôle, c’est l’évaluation finale du modèle, une seule fois, une fois toutes les décisions prises. S’en servir pour choisir
max_depth, c’est le contaminer.La solution : réserver une troisième partie des données, le jeu de validation, uniquement dédié à comparer les valeurs de
max_depth(Figure 3).Trois ensembles, trois rôles distincts : le jeu d’entraînement pour apprendre les règles de coupure, le jeu de validation pour comparer les valeurs de
max_depth, le jeu de test pour l’évaluation finale.On teste trois valeurs de
max_depthet on compare leurs performances sur le jeu de validation. On regarde deux métriques :max_depth.La table parle d’elle-même :
max_depth =6donne la meilleure RMSE et le meilleur R² sur ce jeu de validation. Mais est-ce qu’on peut vraiment lui faire confiance ?Cette approche a deux limites importantes.
Les résultats dépendent du split. Si on tombe sur un jeu de validation particulièrement facile ou difficile, la valeur de
max_depthsélectionnée ne sera pas forcément la meilleure en général. Avec seulement 50 observations en validation ici, l’estimation est bruitée.On gaspille des données. 20% des données d’entraînement ne servent qu’à évaluer l’hyperparamètre. Sur un petit jeu de données, c’est un luxe qu’on ne peut pas toujours se permettre.
La solution à ces deux problèmes, c’est la validation croisée, présentée en détail dans le tutoriel précédent. Plutôt que de réserver un seul jeu de validation fixe, on évalue le modèle sur plusieurs découpages successifs des données d’entraînement et on moyenne les scores. Plus stable, plus fiable, et on utilise toutes les données disponibles.
Et plutôt que de tester trois valeurs à la main, on peut automatiser ça sur une grille de valeurs candidates. C’est ce qu’on appelle le grid search avec CV.